18 Feltáró faktorelemzés (Exploratory Factor Analysis)
A fejezet megértéséhez a főkomponens-elemzésről fejezetben tárgyalt variancia, előfeltétel-vizsgálatok, rotáció és töltések értelmezésének ismerete elengedhetetlen.
A főkomponens-elemzés célja, hogy összegezzük a mért (manifeszt) változókat minél kisebb információvesztéssel (lényegkiemelés). Ehhez képest a (feltáró) faktorelemzés célja, hogy a mért változóink mögött húzódó látens struktúrát feltárjuk.
Míg a főkomponens-elemzés során a teljes varianciával számolunk (a korrelációs mátrix főátlójában 1-esek állnak), addig a feltáró faktorelemzés (EFA) bizonyos típusainál (például a főtengely-analízisnél – PAF, principal axis factoring) a közös varianciát többszörös lineáris regresszióval (SMC, squared multiple correlation) becsüljük meg előre minden változóra vonatkozóan. Más EFA módszerek (pl. Maximum Likelihood, DWLS stb.) pedig iteratív algoritmusokat használnak a paraméterek becslésére.
A faktorelemzés során csak a közös varianciák szerepelnek a korrelációs mátrix átlójában, az egyedi variancia és a hiba nem, így a ténylegesen közös varianciák közötti struktúra feltárására alkalmas.
18.1 Faktorálási eljárások, becslőmódszerek
A faktoranalízis során statisztikai becslési eljárással meghatározzuk, hogy hogyan illeszkedjen a modellünk a megfigyelt korrelációs mátrixhoz. A választásnál a legfontosabb szempont a többváltozós normalitás és a változók mérési szintje; illetve hogy illeszkedési alapú vagy iteratív megközelítést választunk. Ezek olyan matematikai alapok, aminek ismeretére gyakorló pszichológusként nincs feltétlenül szükségünk, de az érdeklődők elolvashatják Tabachnick és Fidell (2019) vonatkozó 13. fejezetét.
χ2 alapú Maximum likelihood (ML) becslőfüggvény
A leggyakoribb általános becslőmódszer a faktoranalízisben. Szigorúan megköveteli a többváltozós normalitást és a skálaváltozókat.
A Maximum Likelihood (ML) becslés során egy Likelihood Ratio próbát végzünk, amely azt vizsgálja, hogy a modellünk által produkált kovarianciamátrix szignifikánsan eltér-e a mért értékekből készített kovarianciamátrixtól. A modellerősségi mutatókat (RMSEA, CFI és TLI) ebből a χ2 eredményből származtatjuk.
Léteznek robusztus változatai (MLM, MLR), amelyek elviselik a normalitás sérülését, de ezeket elsősorban strukturális egyenletmodellezések (SEM) során alkalmazzuk, egyszerű EFA-nál ritkábban elérhetőek.
Súlyozott legkisebb négyzetes módszerek: WLS család
Weighted Least Squares (WLS): Teljes súlymátrixot használ, és nem követeli meg a normál eloszlást. Hátránya, hogy a súlymátrix mérete a változók számával exponenciálisan nő, így stabil eredményhez extrém magas (N ≥ 1000) fős minta szükséges.
Diagonally Weighted Least Squares (DWLS): A WLS praktikusabb változata, amelyet kifejezetten ordinális adatokhoz (Likert-skálákhoz) fejlesztettek. Csak a súlymátrix átlós elemeit használja, így már (N =) 150-200 fős mintán is megbízható. Alapja polikorikus korrelációs mátrix.
Weighted Least Squares Mean-and-Variance-adjusted (WLSMV): Ez a de facto sztenderd a kategorikus változók esetén. A faktorparamétereket DWLS-sel méri, de a standard hibákat és az illeszkedési statisztikákat robusztus korrekciókkal számítja ki, így kompenzálja a normalitás hiányát.
Nem súlyozott legkisebb négyzetes módszerek
Minimum Residual (Minres): Ordinális adatokon (pl. Likert) használjuk, vagy olyan esetben, amikor sérül a többdimenziós normalitás. Polikorikus mátrixokhoz kiváló választás. Minimalizálja a négyzetes maradványértékeket. Nem próbálja meg a korrelációs mátrix főátlóját (a kommunalitásokat) tökéletesen illeszteni, inkább a változók közötti kapcsolatot tisztázza. Analitikus első deriváltakat használ. Ez a modern pszichometriai sztenderd EFA-hoz, főleg ha a DWLS nem érhető el.
Unweighted Least Squares (ULS): A Minreshez képest a teljes reziduális mátrixot minimalizálja, a főátlót is. Szintén első deriváltakat használ. Használjuk ezt, ha a DWLS és robusztus társai nem elérhetőek (Forero és mtsai., 2009).
Ordinary Least Squares (OLS): Szintén a teljes reziduális mátrixot minimalizálja. Minden maradványértéket azonos súllyal kezel, függetlenül a változó varianciájától. Robusztus változata az ULSMV, amely akkor hasznos, ha a normalitás súlyosan sérül, és a DWLS feltételei sem állnak fenn. Empirikus deriváltakat használ, ami miatt lassabb.
Generalized Least Squares (GLS): Nagyobb súlyt ad a „precízebben” mért, azaz kisebb varianciájú változóknak. Az Maximum likelihood módszerhez hasonlóan feltétele a többváltozós normalitás. Kis mintán teljesen megbízhatatlan, ezért a gyakorlatban ritkábban alkalmazzuk.
Egyéb módszerek
Főfaktor-analízis, Principal Axis Factoring (PAF): Az EFA egyik leggyakrabban használt extrakciós módszere. A PAF iteratív eljárással becsli meg a kommunalitásokat. Nem feltételezi a változók normál eloszlását, ezért rendkívül robusztus klinikai vagy kérdőíves adatok esetén (Fabrigar és mtsai., 1999).
Minimum Rank Factor Analysis (MRFA): Ez az eljárás azokat a faktorsúlyokat keresi meg, amelyek mellett a maradványértékek korrelációs mátrixának átlón kívüli elemeinek négyzetösszege a legalacsonyabb lesz.
A fenti egy általános áttekintő a módszerekről. Különböző szoftverekben különböző becslőmódszerek érthetőek el. Például a JASP Factor moduljaiban az R szoftver psych csomagjának módszerei érhetők el, míg a strukturális egyenletrendszerekhez használt modulban (SEM) a lavaan csomag eljárásai.
| Becslőmódszer | JASP EFA | JASP CFA, SEM | Többdimenziós normalitást igényel | Ordinálishoz való | Polikorikus korrelációs mátrixhoz használható |
|---|---|---|---|---|---|
| Maximum likelihood (ML) | Igen | Igen | Igen | Nem | Nem ajánlott |
| Minimum Residual (Minres) | Igen | Nem | Nem | Igen | Igen |
| Principal axis factoring (PAF) | Igen | Nem | Nem | Igen | Igen, de kevésbé precíz szemben az LS típusúakkal |
| Ordinary Least Squares (OLS) | Igen | Nem | Nem | Igen | Igen |
| Unweighted Least Squares (ULS) | Nem | Igen | Nem | Igen | Igen |
| Generalised Least Squares (GLS) | Igen | Igen | Igen | Nem | Nem ajánlott |
| Diagonally Weighted Least Squares (DWLS) | Nem | Igen | Nem | Igen | Igen |
| Weighted Least Squares Mean-adjusted (WLSM) | Nem | Igen | Nem | Igen | Igen |
| Weighted Least Squares Mean-and-Variance-adjusted (WLSMV) | Nem | Igen | Nem | Igen | Igen |
| Weighted Least Squares (WLS) | Nem | Igen | Nem | Igen | Igen, de extrém nagy minta szükséges |
18.2 Modellilleszkedés vizsgálata
A modellilleszkedési mutatókat típusaik szerint feloszthatjuk az alábbi kategóriákra:
- Abszolút illeszkedést mérő mutatók (azt mérik, mennyire tér el a modell a megfigyelt adatoktól): χ2, SRMR, WRMR, GFI, AGFI és itt nem tárgyalt Hoelter CN
- Noncentralitás alapú mutatók (a χ2 eloszlás noncentralitási paraméteréből származtatott mutatók): CFI, RMSEA és az itt nem tárgyalt RNI, CI, MFI
- Inkrementális, relatív mutatók (a vizsgált modellt egy függetlenségi modellhez viszonyítják): TLI (matematikailag azonos: NNFI), és ide is sorolható lenne a CFI1, és itt nem tárgyalt IFI, NFI
- Modellszelekciós információs kritériumok és prediktív illeszkedési mutatók (modellek összehasonlítására, kiválasztásra használjuk): BIC, SABIC és az itt nem tárgyalt AIC, ECVI
- Parszimónia-alapú mutatók, amiket nem tárgyaltunk (az illeszkedést a modell komplexitásával, vagyis a szabadságfokkal súlyozzák): PGFI, PNFI és PNFI2, PCFI
A főbb mutatókat az alábbiakban találjuk:
Az alapvető abszolút modellilleszkedési mutató egy χ2 próba. Alacsony p-érték (és kimondottan szignifikáns eredmény) rossz modellilleszkedésre utal, de nagy mintaelemszámnál túlságosan érzékeny a próba. A nyers khí-négyzet próba eredménye helyett a gyakorlatban az alábbi mutatókat vesszük figyelembe.
Khí-négyzet és szabadságfok aránya (χ2/df) < 2 kiváló illeszkedést jelez (Cole, 1987), míg < 5 érték számított elfogadhatónak korábban (Wheaton és mtsai., 1977), de a gyakorlati elvárt középút a < 3.
Összehasonlító illeszkedés mutató (CFI, Comparative Fit Index) azt vizsgálja, hogy a feltételezett modellünk mennyire jó illeszkedésű a függetlenségi modellhez. Csupán 0 és 1 közötti értéket vehet fel. > 0,90 értéket többen még megfelelőnek tartanak, de a > 0,95 érték számít kiválónak (Hu és Bentler, 1999).
\[ \text{CFI} = 1 - \frac{\max(\chi^2_m - df_m, 0)}{\max(\chi^2_m - df_m, \chi^2_b - df_b, 0)} \]
Tucker-Lewis Index (TLI) vagy Non-normed Fit Index (NNFI) a CFI nem normalizált változata (nem csupán 0-1 között vehet fel értéket). Kimondottan bünteti a túl komplex modelleket. Ugyanolyan kritériumértékekkel rendelkezik, mint a CFI. 1 fölötti érték annyit jelent, hogy a χ2/df arány kisebb, mint 1: a modell túl jól illeszkedik a mintához, túl kicsi a minta, mintavételi hibánk van, vagy túlspecifikált a modell. A CFI-hez hasonlóan értelmezzük: ideálisan > 0,95 (de legalább > 0,90).
\[ \text{TLI} = \frac{\frac{\chi^2_b}{df_b} - \frac{\chi^2_m}{df_m}}{\frac{\chi^2_b}{df_b} - 1} \]
Megközelítési négyzetes középérték hiba (RMSEA, Root Mean Square Error of Approximation) az illeszkedési χ2 próbát korrigálja szabadságfokkal és a populációs hibát becsli a szabadságfok és minta nagysága alapján. Ez a mutató szintén érzékeny a modellek komplexitására.
\[ \text{RMSEA} = \sqrt{\text{max}(0, \frac{\chi^2-\text{df}}{\text{df}(N-1)})} \]
Legrégebbi szerzők alapján < 0,05 szoros illeszkedés, < 0,08 elfogadható közelítés, de 0,10-nél magasabb érték már elutasítandó modell (Browne és Cudeck, 1992). Mások szerint < 0,01 kiváló, de nem realisztikus (MacCallum és mtsai., 1996). A kutatásokban leggyakrabban az RMSEA ≤ 0,06 értékkel találkozunk (Hu és Bentler, 1999). Újabb szerzők szerint < 0,07 elfogadható, míg < 0,03 érték ideális (Steiger, 2007), vagy strukturális egyenletmodellekhez gyakorlatisan < 0,05 (Byrne és Byrne, 2013).
Újabban a 90% konfidenciaintervallumot is meg szoktuk adni, felső értékére lehetőleg < 0,10 alatti kell legyen.
Standardizált reziduális négyzetes középérték (SRMR, Standardised Root Mean Square Residual) globális illeszkedést vizsgáló mutató a megfigyelt és a modell által becsült korrelációs mátrix elemei közötti különbségek négyzetei átlagának a négyzetgyöke. Értéke 0 és 1 között lehet. 0 a tökéletes illeszkedés.
\[ \text{SRMR} = \sqrt{\frac{2\sum_{i=1}^{p}\sum_{j=1}^{i-1} \left[ \frac{s_{ij}}{\sqrt{s_{ii}s_{jj}}} - \frac{\hat{\sigma}_{ij}}{\sqrt{\hat{\sigma}_{ii}\hat{\sigma}_{jj}}} \right]^2}{p(p+1)}} \]
SRMR ≤ 0,08 értéke számít ideálisnak (Hu és Bentler, 1999). A mutató lefelé torzít nagy minta esetén, kis minta (N < 200) esetén pedig felfelé (tehát a 0,08-as érték itt túl szigorú). Nem bünteti a komplexitást, mert nem számol szabadságfokkal. Mások szerint itt is a ≤ 0,05 érték jelzi a jó illeszkedést, míg a ≤ 0,10 elfogadható szint (Schermelleh-Engel és mtsai., 2003).
Bayesiánus információs kritérium (BIC, Bayesian Information Criterion) egy összehasonlító mutató, tehát modellek közötti választás során az alacsonyabb értékűt tekintjük jobbnak. Altípusa a SABIC (Sample-Size Adjusted BIC), ami a mintaelemszámmal korrigál, és látens osztályalanízisben (LCA) kis (N < 200) minta esetén javasolt a használata a csoportok számának meghatározására.
Regresszióanalízis alapú legkisebb négyzetek (OLS) becsléssel:
\[ \text{BIC} = n \ln\left(\frac{\text{SSE}}{n}\right) + (k+1) \ln(n) \]
ML becsléssel:
\[ \text{BIC} = -2\ln\left(L\right) + p \ln(N) \]
(Korrigált) illeszkedés jósága mutató (GFI, Goodness of Fit és AGFI Adjusted Goodness of Fit) elavultnak számít, mert mintaelemszám növekedésével erősen felfelé torzít. A statisztikai programok még gyakran megjelenítik, folyóiratok még kérhetik, ha kihagyjuk, de ne használjuk értékelésre.
\[ \text{GFI} = 1 - \frac{\text{Tr}\left[ \left( \hat{\Sigma}^{-1} S - I \right)^2 \right]}{\text{Tr}\left[ \left( \hat{\Sigma}^{-1} S \right)^2 \right]} \]
\[ \text{AGFI} = 1 - \left[ \frac{p(p+1)}{2df} \right] (1 - \text{GFI}) \]
Súlyozott reziduális négyzetes középérték (WRMR, Weighted Root Mean Square Residual) az SRMR olyan változata, amelyik a varianciával súlyoz. A mintaelemszám növelésével romlik a mutató értéke. Jelenleg kevésbé gyakori a használata. ≤ 1,0 érték elfogadható. WLSMV mellett preferáljuk az SRMR-rel szemben, de nem minden szoftver számolja ki.
\[ \text{WRMR} = \sqrt{\frac{\sum_{i=1}^{p} \sum_{j=1}^{i} w_{ij} (s_{ij} - \hat{\sigma}_{ij})^2}{\sum_{i=1}^{p} \sum_{j=1}^{i} w_{ij}}} \]
Kline (2016) javaslata alapján legalább a modell χ2 értékét, az RMSEA (90% CI értékkel), CFI és SRMR mutatót kell bemutatni. Emellett a TLI mutató használata is gyakori.
18.3 Struktúramátrix (Structure Matrix) vs Mintázatmátrix (Pattern Matrix)
A Struktúramátrix (Structure Matrix) a változók (itemek) és a látens faktorok becsült korrelációs mátrixa, ami a szorzatmomentumot, vagyis Pearson-féle korrelációs együtthatót tartalmaz kontrollálás nélkül, tehát tartalmazza a többi faktor adott itemre értendő hatását is. Pszichometriában nem ezt használjuk.
A Mintázatmátrix (Pattern Matrix) vagy forgatott faktorsúlymátrix (rotated factor load matrix) a standardizált regressziós koefficienseket tartalmazza, ami megmutatja, hogy az adott változóra milyen közvetlen hatással van az adott faktor, miközben kontrollálunk a többi faktor hatására (l. parciális korreláció). Ferde (oblique) rotáció alkalmazásakor a struktúramátrixtól jelentősen eltér, és kimondottan a mintázatmátrix alapján állítjuk fel a modellünket és ennek az eredményét jelentjük a szakcikkben is (Osborne és mtsai., 2008).
18.4 Példa feltáró faktoranalízisre
A főkomponenselemzésről szóló fejezetben leírt példát és adatsort használjuk ismét.
Az EFA-t a Factor / Exploratory Factor Analysis modulban végezzük el. Beállítjuk a vizsgálatot az alábbiak szerint:
- Number of factors szekcióban a Based on rovaton belül a Horn-féle parallelanalízist választjuk (Parallel analysis), azon belül pedig - mivel faktoranalízist végzünk - a FA opciót választjuk.
- Rotáció az Analysis Options szekcióban: mivel tudjuk, hogy személyiségjellemzőket vizsgálunk, és a személyiség konstruktumok között mindig van korreláció, pszichometriai módszertani hiba lenne derékszögű (ortogonális) rotációt használni. A szakmai konszenzus alapján ferde (oblique) rotációt választunk. Használjuk a promax rotációt is mint default (Osborne és mtsai., 2008), ahogy a főkomponenselemzéses példában is, vagy használjuk az oblimint.
- Az Analysis Options szekcióban a Factoring method listából válasszuk ki a megfelelő módszert majd: ha a Mardia-féle többdimenziós normalitás próba szignifikáns, akkor semmiképpen sem válaszhatunk Maximum likelihood (default) módszert, sem olyat, ahol a többdimenziós normalitás feltétel. Ordinális adatok esetén JASP EFA modulban használjuk a Minimum residual, Ordinary least squares vagy Principal axis factoring módszert a polikorikus korrelációs mátrixhoz ordinális adatokon.
- Mátrix kiválasztása a Base Decomposition on szekcióban: tudjuk, hogy polikorikus korrelációs mátrixot főleg ordinális adatoknál, vagy kimondottan Likert tételeknél célszerű használni. Az egyetlen jó választás, ha a Mardia-féle mutatók szignifikánsak. (Ezt később meglátjuk!)
- Az Output options szekcióban…
- állítsuk be, hogy a |0,3| fölötti komponenstöltéseket láthassuk (az alapbeállítás 0,4): Display loadings above
- állítsuk be, hogy a komponenstöltések táblázatában ne a töltések erőssége, hanem a változók nevének sorrendjében jelenjenek meg a változóink: Order Loadings By Variables
- állítsuk be, hogy a hiányzó értékeket (Missing Values) listwise töröljük! Ez esetben az elemzés minden olyan adatsort kihagy, ahol hiányzó érték szerepel. Ha a pairwise opciót választjuk, akkor több adatunk marad meg az elemzéshez, de a torzítás is nő, vagy fennáll a kockázata az inkonzisztens korrelációs mátrixok előállásának.
- pipáljuk ki a Tables rovatban a Factor correlations lehetőséget, mert ferde rotációt alkalmaztunk és tudni szeretnénk, hogy milyen korreláció áll fenn a főkomponensek között.
- pipáljuk ki a Tables rovatban az Additional fit indices lehetőséget, hogy a modellilleszkedési mutatókat kiszámítsuk.
- pipáljuk ki a Tables rovatban a Residual matrix lehetőséget, mert ellenőriznünk kell, hogy a modellünk maradványértékei alacsonyak.
- pipáljuk ki a Plots rovatban a Scree plotot és a Parallel analysis results-t, ami alapján döntünk a megtartott komponensek számáról.
- pipáljuk ki az Assumption cheks szekció összes mezőjét, de minimum a KMO test, Bartlett’s test és FA esetén a Mardia’s test opciókat!
- Olvassuk le az előfeltétel-vizsgálatok eredményeit!
Ne lepődjünk meg, hogy hogy ugyanazokat az eredményeket kapjuk, mint a főkomponenselemzéses példánál, mert ugyanazoknak az adatoknak a redukálhatóságát és faktorálhatóságát, valamint többdimenziós normalitását vizsgáljuk. Emlékeztetőül:
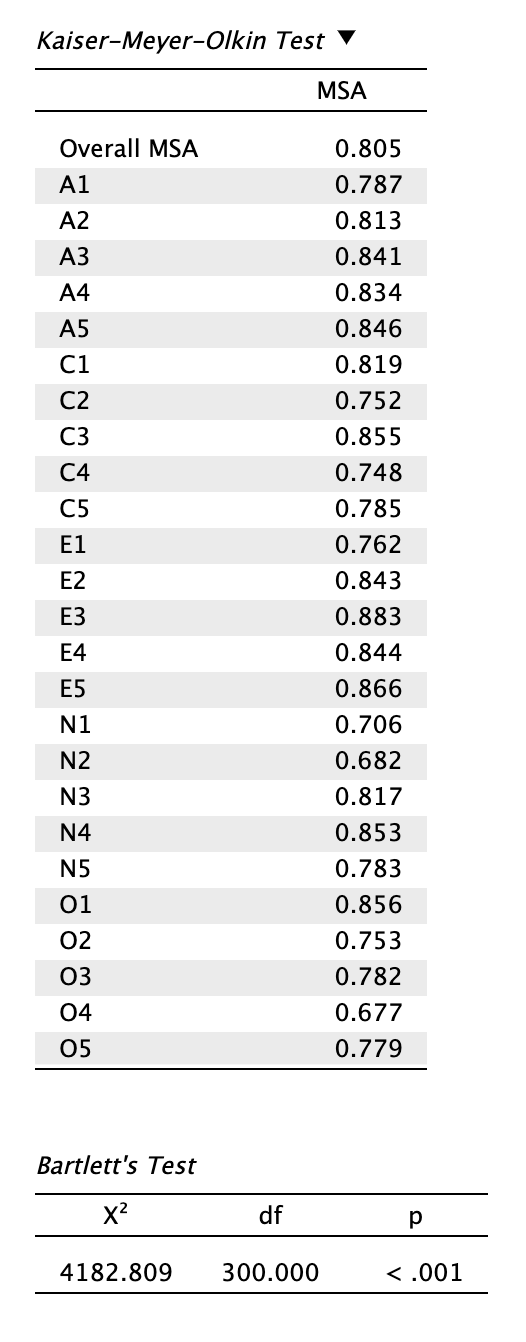
Láthatjuk, hogy a Kaiser-Meyer-Olkin-féle megfelelőségi mutató (Overall MSA) értéke 0,805, ha a polikorikus korrelációs mátrixot2 választottuk. Ez dicséretes Kaiser (1974) alapján, vagy ideális Hair és mtsai. (2019) alapján.
Az egyes tételekhez tartozó Measures of Sampling Adequacy mutatók (MSA) vegyesebb képet mutatnak: 0,677 (O4 tétel) és 0,883 (E3 tétel) között mozognak. Egyik tétel pontszáma sem 0,5 alatti, ezért nem kötelező törölnünk tételeket a modellből. Eldönthetjük, hogy kihagyjuk-e őket az elemzésből, ha erős elméleti alapunk van rá, vagy csupán jelentjük őket szövegesen. Ebben a példában értelemszerűen ez utóbbit választjuk.
A Bartlett-féle szférikusságpróba eredménye szignifikáns, vagyis a tételek közötti korreláció elégséges főkomponens-elemzéshez (és faktoráláshoz): a korrelációs mátrix nem egységmátrix.
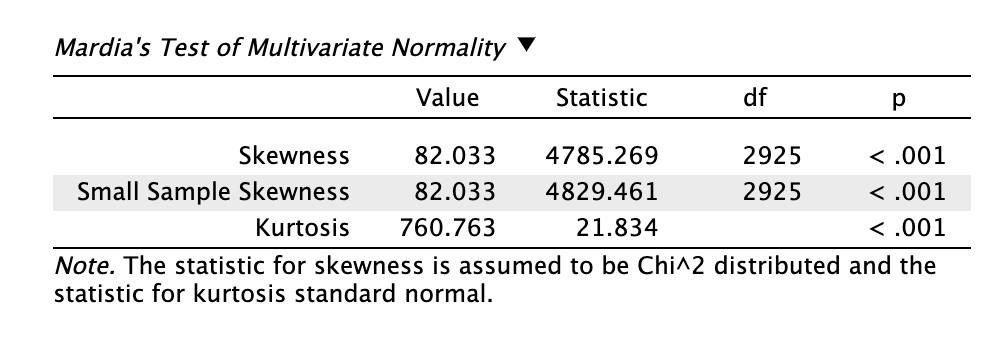
A többváltozós normalitás vizsgálata során azt látjuk, hogy mind a túlzott ferdeség, mint a túlzott csúcsosság fennáll (szignifikáns mindegyik próba). Ezért Pearson-féle korrelációs mátrixot használni nem javallot. Helyette a polikorikus korrelációs mátrix használata célszerű (nem hiába választottuk azt a biztonság kedvéért alapválasztásként).
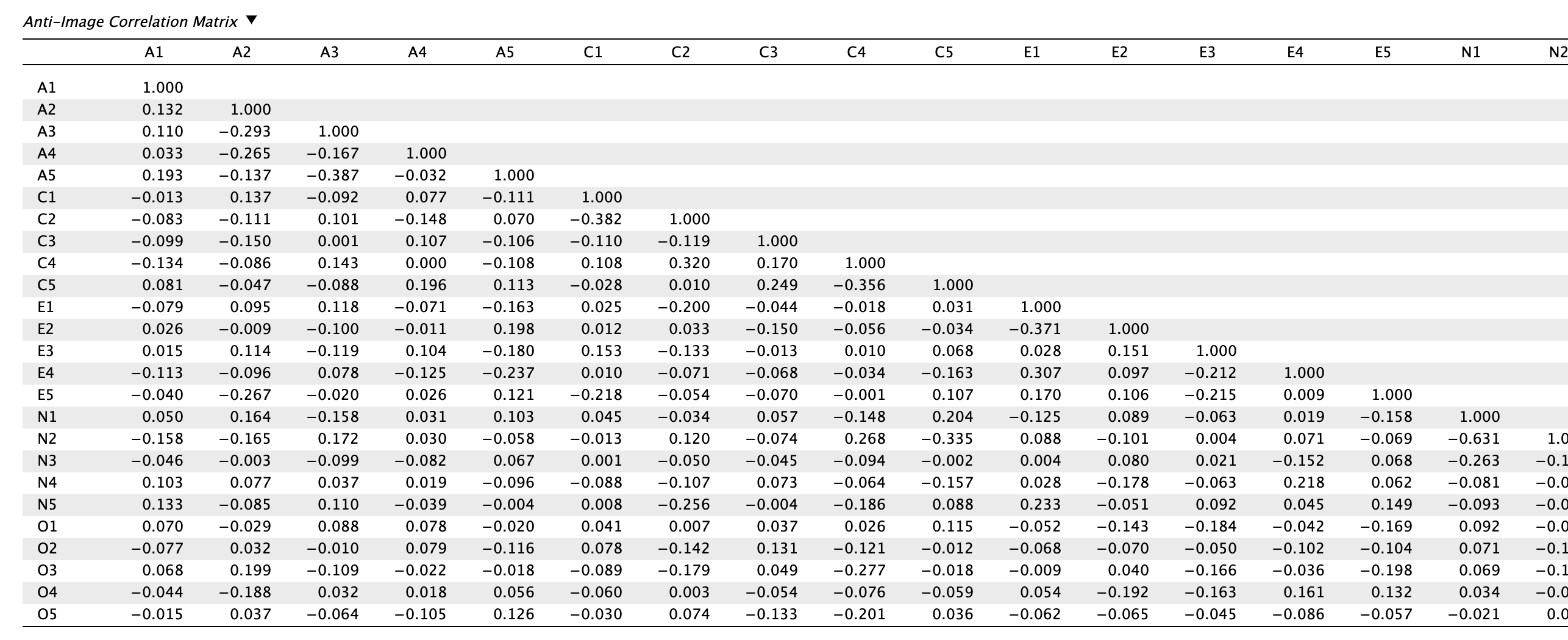
Az anti-image korrelációs mátrixot áttekintjük, és megvizsgáljuk, hogy vannak-e nullánál lényegesen nagyobb tételek (≥ 0,09) abszolút értékben. Sajnálatos módon több tételpárnál láthatunk nagyon magas parciáliskorrelációs értékeket, például:
- N1-N2: -0,631
- A3-A5: -0,387
- C1-C2: -0,382
- E1-E2: -0,371
- N3-N4: -0,368
Ez azt jelenti, hogy a mátrix jelenleg nem optimális, mert az itemek között páronként szisztematikus variancia van, amelyeket a főkomponens-elemzésben felállított főkomponensek nem fognak megfelelően lefedni, így például redundáns faktorok/komponensek állhatnak elő. Pszichometriai szempontból érdemes megvizsgálni, hogy például az N1 és N2 tételek nem mérik-e nagyon szűken ugyanazt a jelenséget.
Együttesen az előfeltételvizsgálatok azt az eredményt adják, hogy az adatstruktúra alkalmas főkomponenselemzésre (és faktoranalízisre is), az MSA értkek stabilak, bár egyes tételek túl hasonló varianciát hordoznak, ezért várhatóan nagyon magasan töltenek majd ugyanarra a komponensre.
- Nézzük meg a scree plotot és a parallelanalízis eredményét!
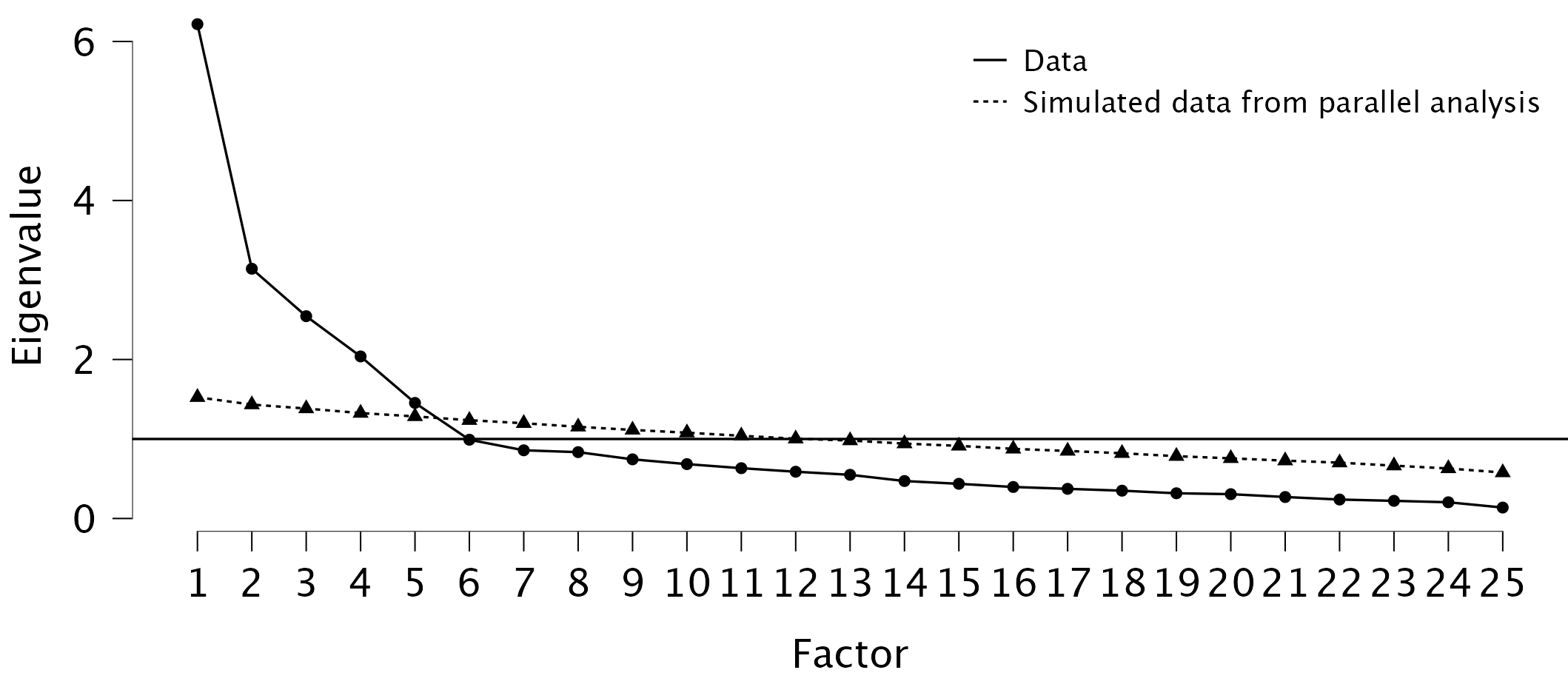
Láthatjuk, hogy ha pusztán a könyökábra meredekség-csökkenése alapján értékelnénk, akkor vagy két komponenst tartnánk meg, vagy hatot. Ha a Kaiser—Guttman-kritérium alapján ítélünk (eigenvalue > 1), akkor éppenhogy 5-t. A Horn-féle parallelanalízis — ami a modernebb kritérium — eredménye 5 főkomponens. (Mellékesen tudjuk, hogy a Big Five itemek 5 komponenst kellene eredményezzenek.)
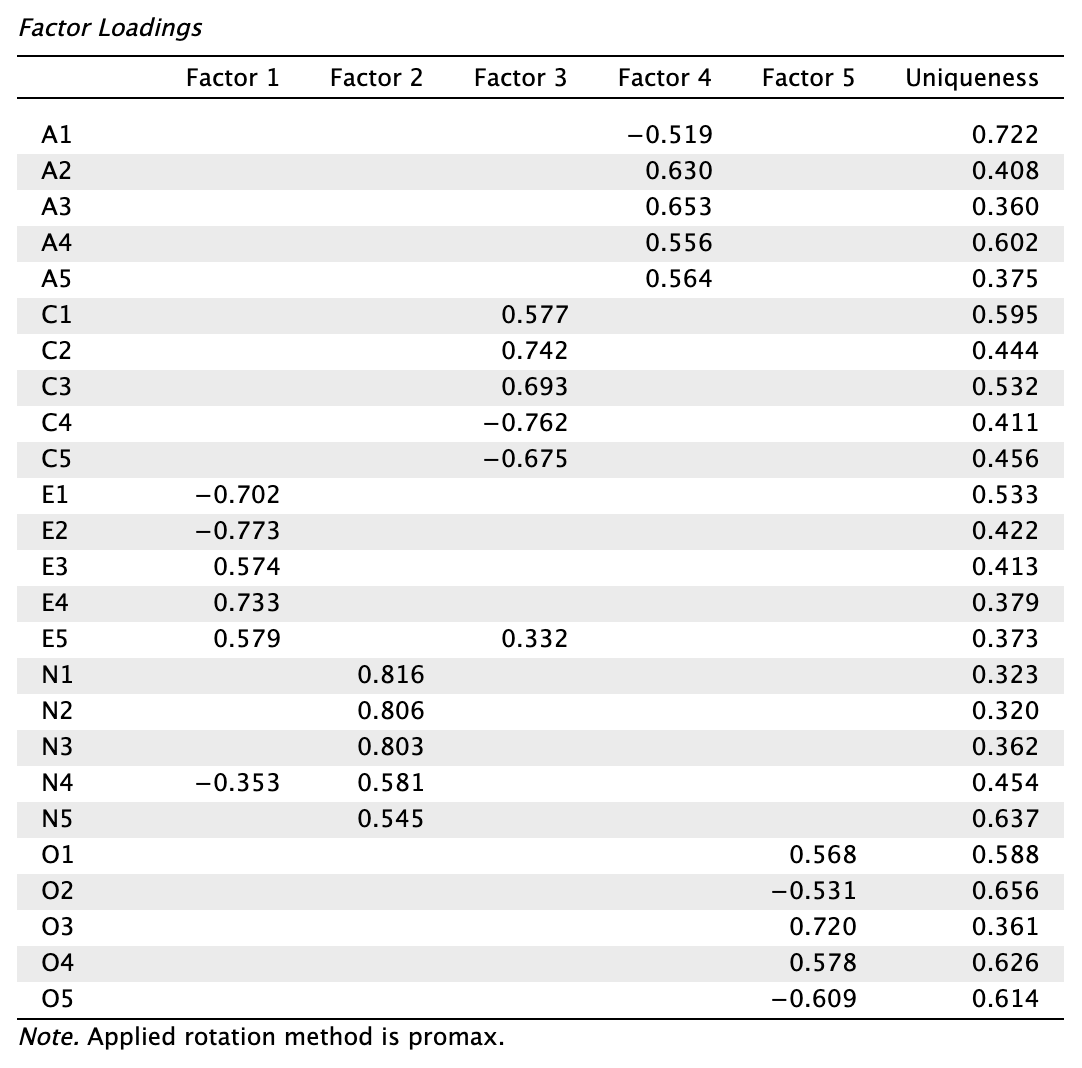
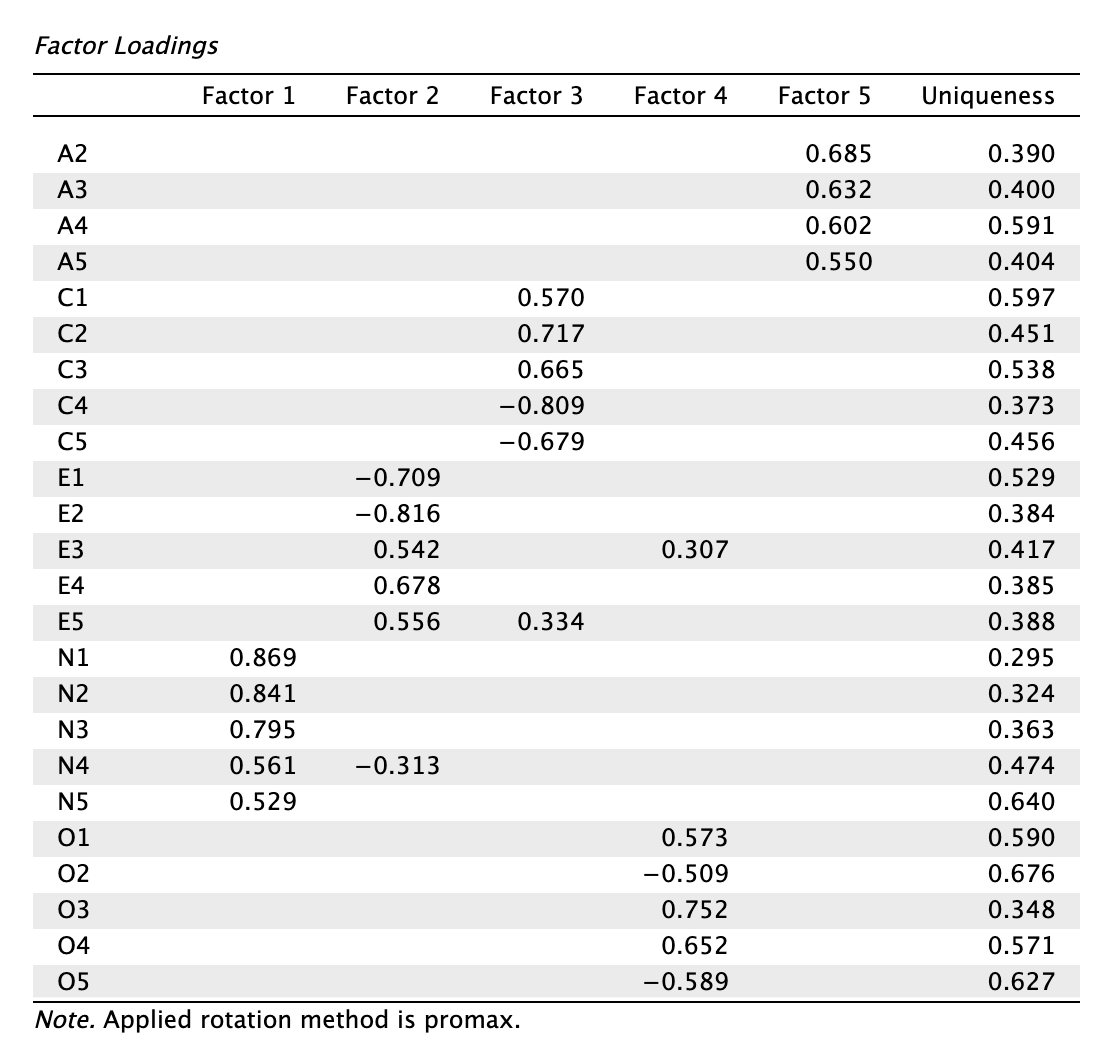
- Olvassuk le rotált töltéseket a Factor Loadings táblázatban és vizsgáljuk meg a kezdeti modellilleszkedési mutatókat is!
A Structure Matrix táblázatot nem használjuk értelmezésre, nem is pipáltuk ki. Helyette a mintázatmátrixot vizsgáljuk (JASP-ban Factor Loadings fejlécű táblázat).
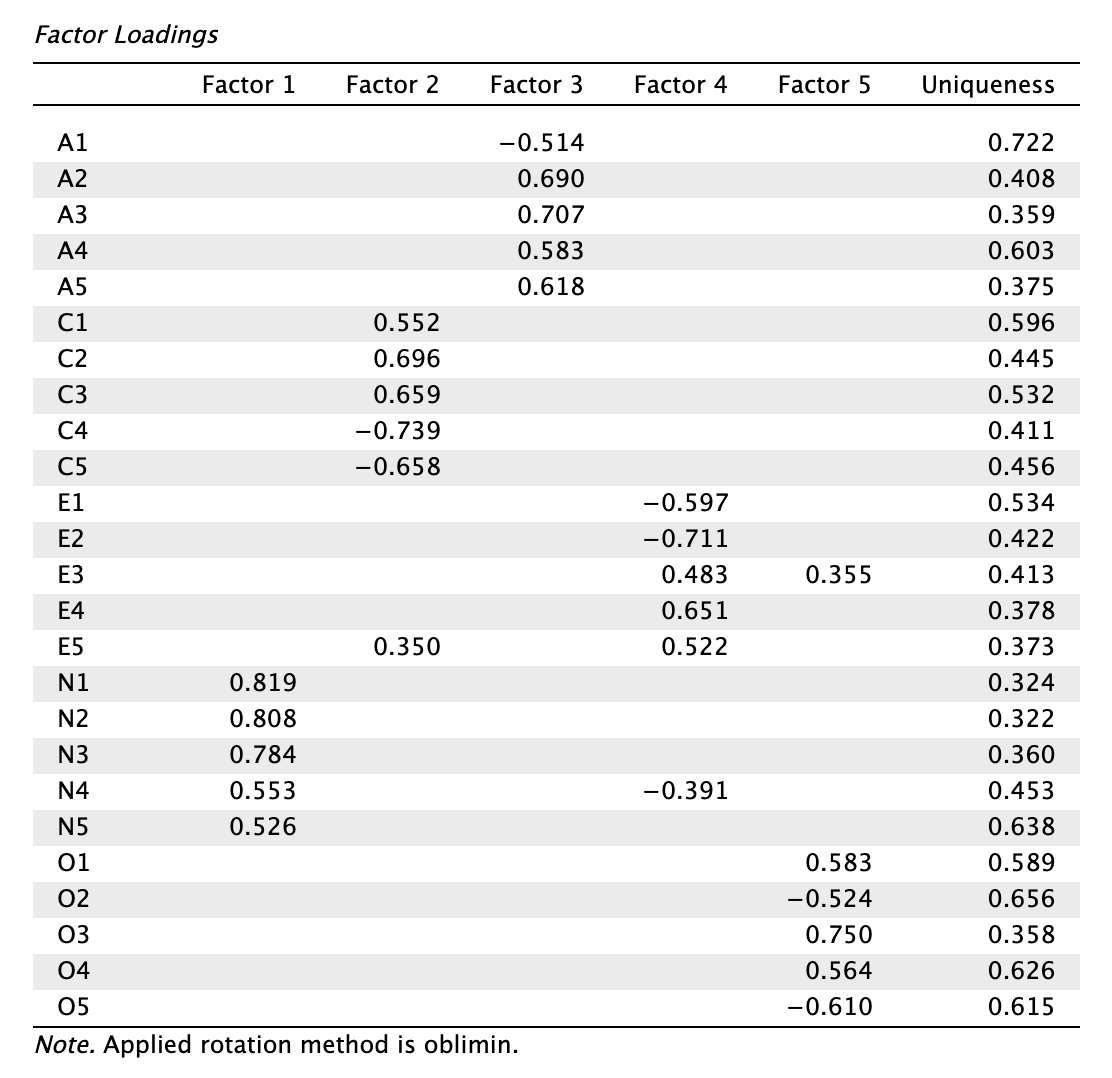
OLS becslés megoldásai:
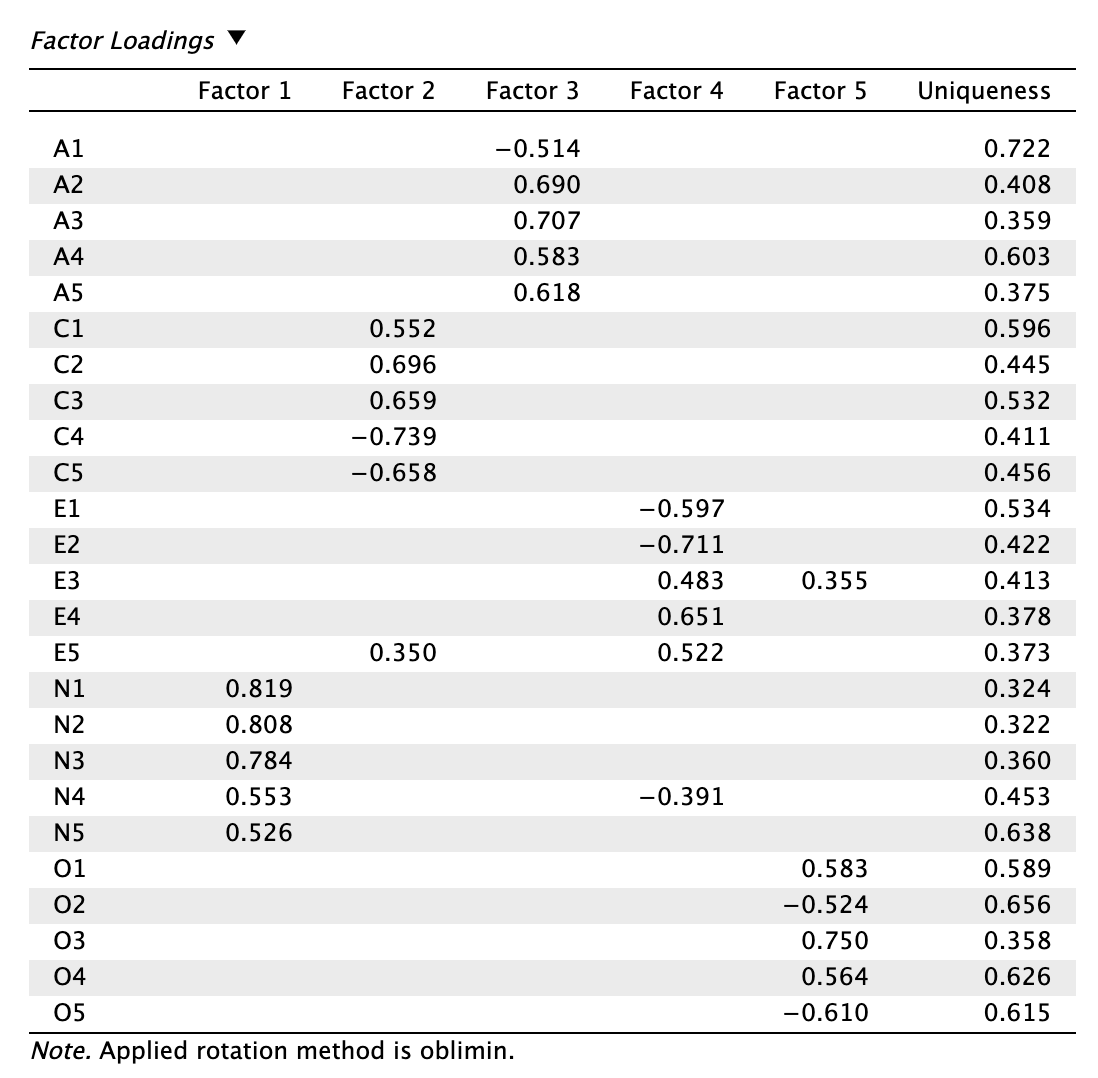


Minimum residual (Minres) becslés megoldásai:
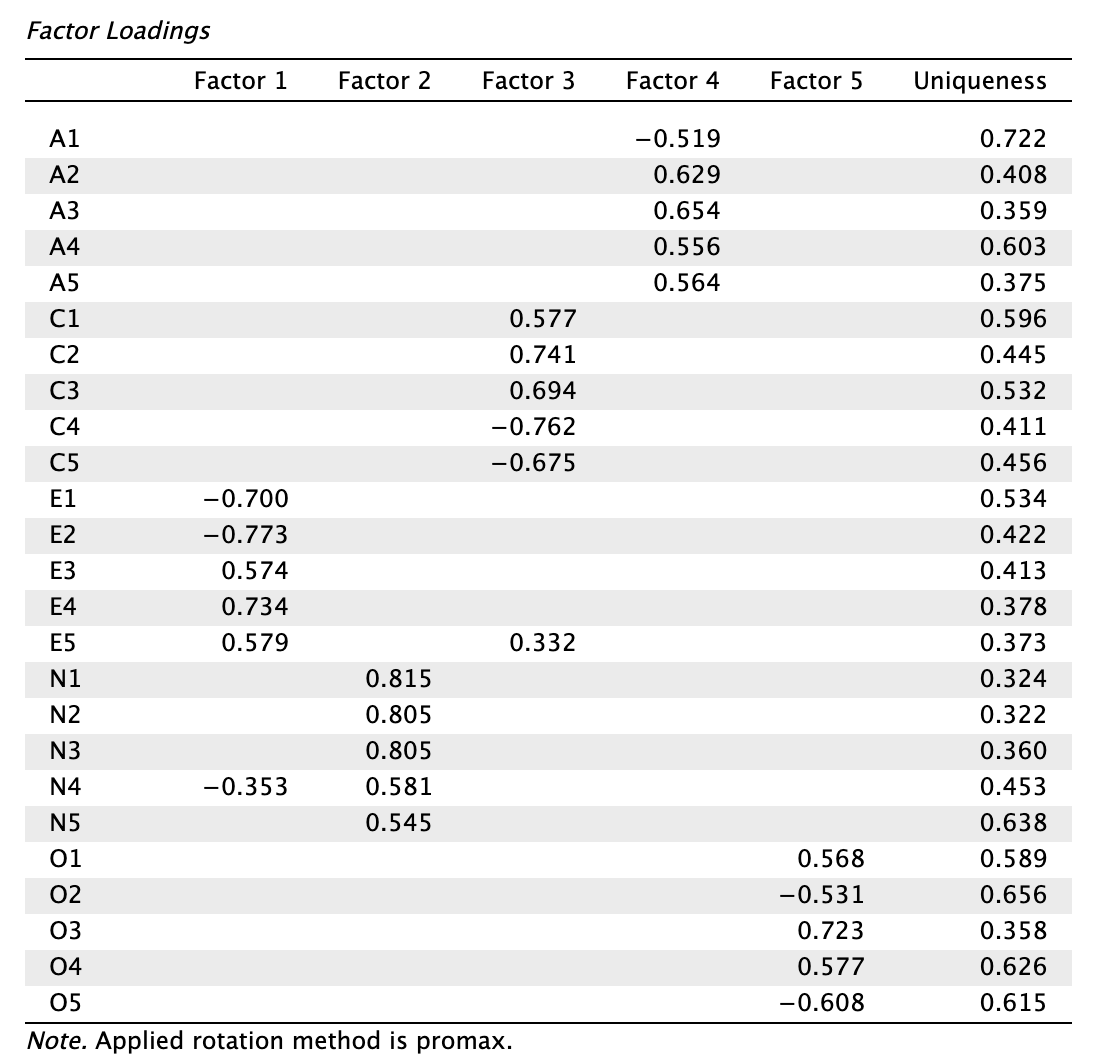


Principal axis factoring (PAF) becslés megoldásai:
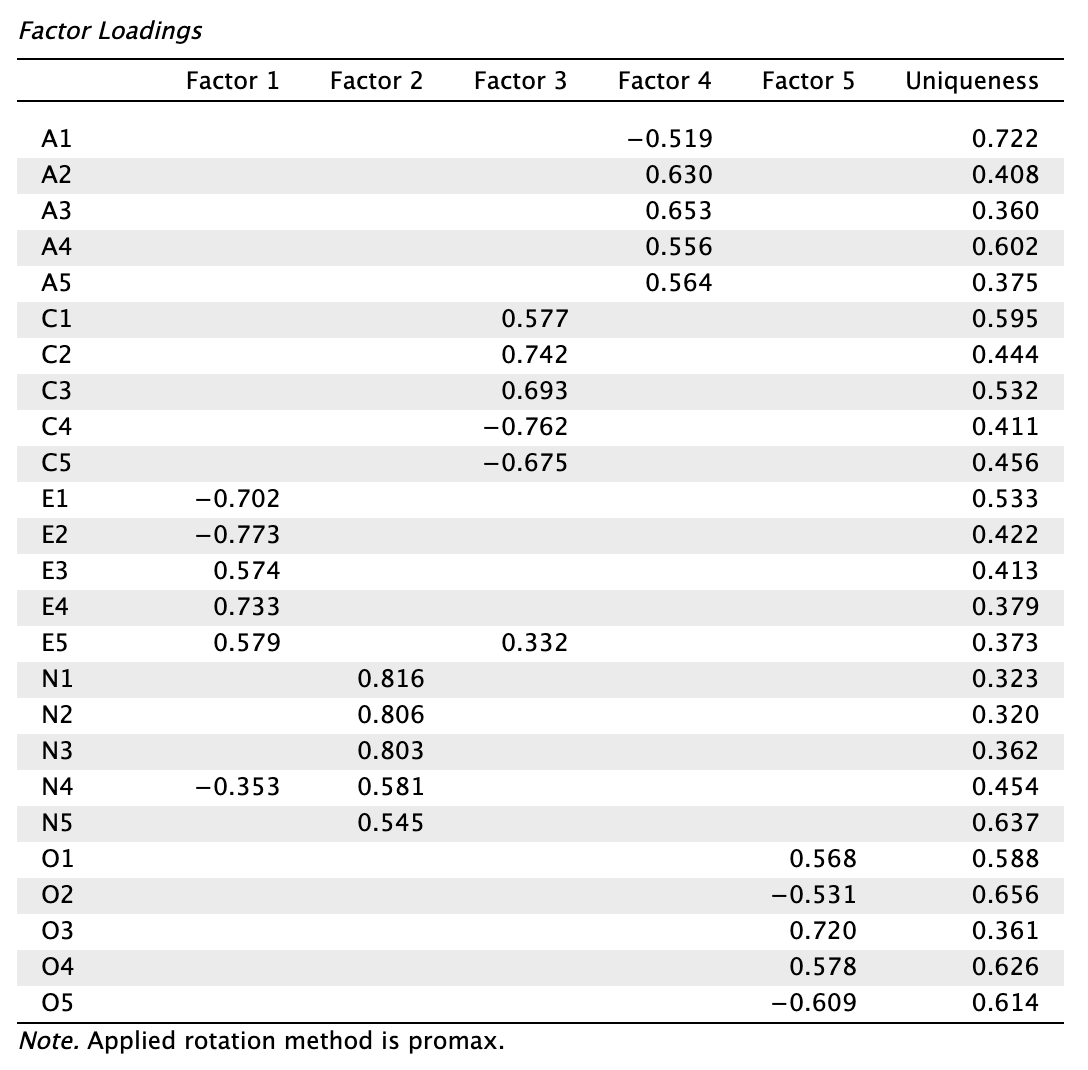
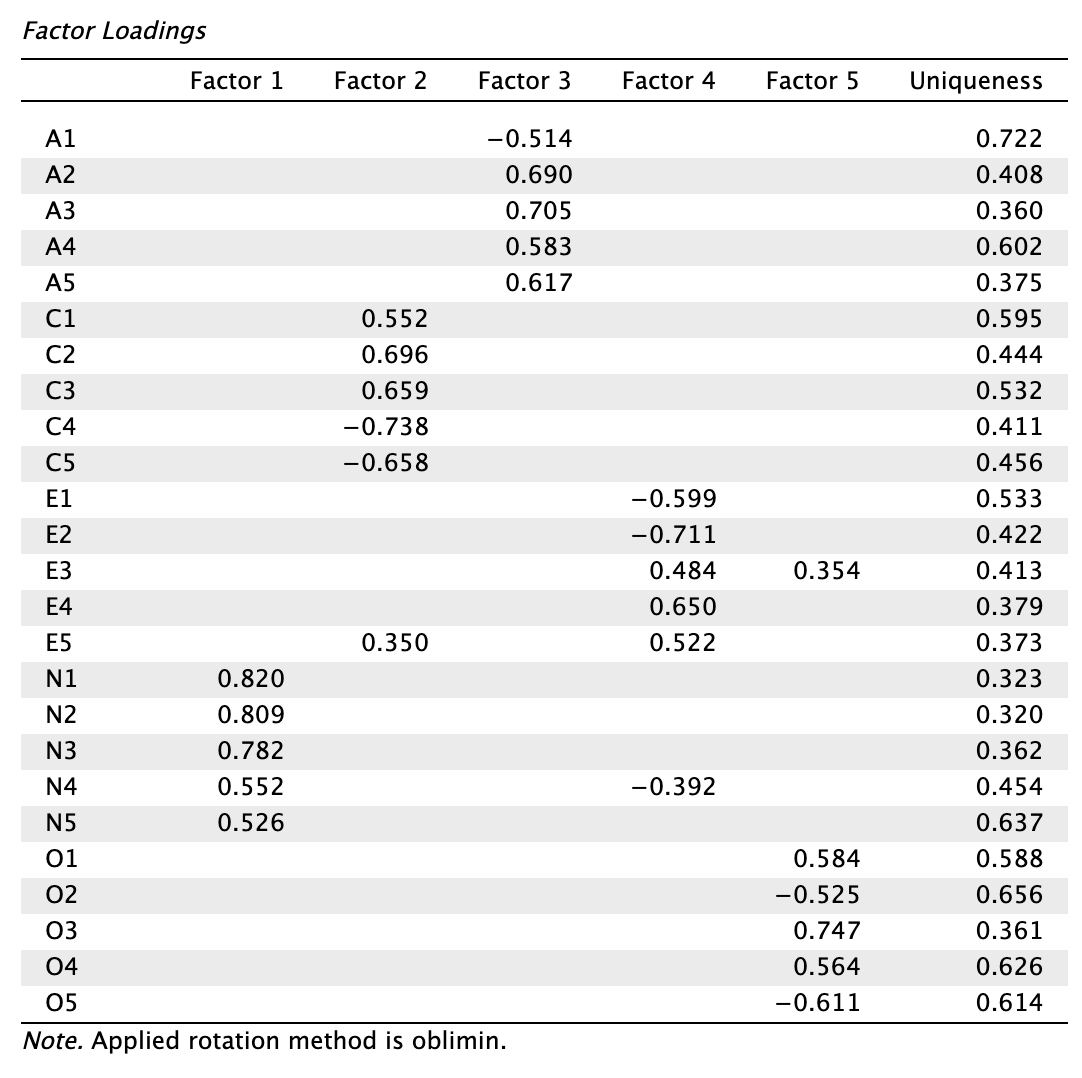


Hasonlítsuk össze a modellek mutatóit:
| Módszer | Forgatás | Átlagos elsődleges töltés | Legnagyobb kereszttöltés | 0,3 alatti elsődleges töltések | 0,3 fölötti kereszttöltések |
|---|---|---|---|---|---|
| OLS | Promax | 0,652 | 0,353 | - | 2 |
| OLS | Oblimin | 0,636 | 0,391 | - | 3 |
| Minres | Promax | 0,652 | 0,353 | - | 2 |
| Minres | Oblimin | 0,636 | 0,391 | - | 3 |
| PAF | Promax | 0,651 | 0,353 | - | 2 |
| PAF | Oblimin | 0,636 | 0,392 | - | 3 |
Láthatjuk, hogy a becslőmódszertől függetlenül a promax forgatás eredményezte a magasabb elsődleges töltéseket, és legalacsonyabb és legkevesebb kereszttöltést. Forgatási mód szerint a promaxot részesítjük előnyben az obliminhez képest a továbbiakban.
Mivel a becslőmódszerek között nem volt különbség, az alábbiak szerint választunk:
- PAF módszer alkalmas lenne a nem normál adatokkal való munkára (és nagyon sok pszichológiai kutatás használta ezt a múltban), de nem választjuk, mert a polikorikus korrelációs mátrixon kevésbé precíz az LS típusú becslőkel összevetve.
- OLS módszer is alkalmas lehet, de a teljes mátrixot (átlóval együtt) priorizálja, ezért a gyakorlati javaslat a Minimum residual módszer EFA-hoz.
A továbbiakban a Minimum Residual becslővel és promax forgatással létrehozott eredményekkel folytatjuk.
Vizsgáljuk meg alaposan a mintázatmátrixot. Vegyük észre, hogy több tétel egyedisége (Uniqueness) kritikusan magas. Emlékezzünk: magas egyediség (> 0,6) azt jelenti, hogy a változó nagy részében egyedi variancia vagy mérési hiba található, alacsony a kommunalitás. Listázzuk ki azokat a változókat, amelyeknél 0,6 fölötti egyediséget tapasztalunk (egyediség szerinti csökkenő sorrendben): A1, O2, N5, O4, O53, A4. Látjuk, hogy a C1 item egyedisége is 0,596-tal erősen megközelíti a 0,6-os korlátot. Azonban az egyediségre vonatkozó korlátot szakmaiatlan lenne szigorú cutoffként értelmezni.
A diagnosztikai és javítási lépések iteratívak (egyszerre egy dolgot emelünk ki a modellből) és kombináltak (Osborne és mtsai., 2008). Egyszerre kell vizsgálnunk:
- Az egyediséget: 0,40–0,70 közötti kommunalitás a norma a szociológiai-pszichológiai kutatásokban, ami 0,30-0,60 egyediséget jelent
- És hogy társul-e hozzá alacsony faktortöltés és magas kereszttöltés?
Láthatjuk, hogy két tételünk van (E5 és N4), amelyeknek magas a kereszttöltése, de mindkettő a 0,2-es különbségsávon belül van az elsőleges töltéshez képest, és egyediségük megfelelő.
Láthatjuk, hogy az A1 tétel faktortöltése a legalacsonyabb, és a legmagasabb egyediség társul hozzá. Ezt a tételt kivesszük a modellünkből.

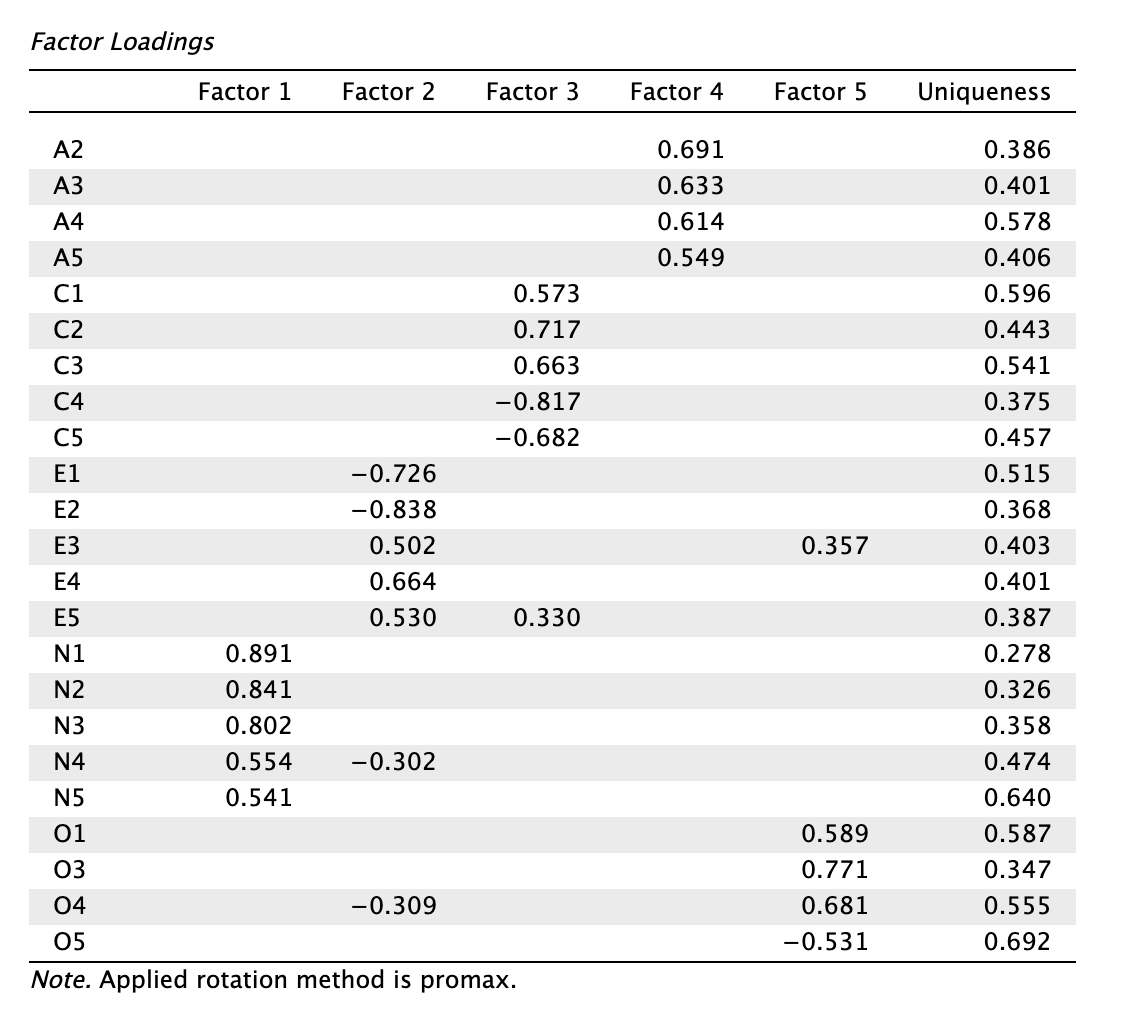
Az láthatjuk, hogy:
- Az RMSEA mutató marginálisan romlott: 0,091 → 0,093, 90% CI felső határa: 0,098 → 0,101
- Az SRMR mutató marginálisan javult: 0,038 → 0,037
- A TLI mutató marginálisan javult: 0,774 → 0,777
- A CFI mutató marginálisan javult: 0,862 → 0,867
- A BIC mutató romlott4, mert a kisebb (negatívabb) a jobb: -363,764 → -303,180
- Az A4 tétel töltése jelentősen nőtt (0,556 → 0,602), az egyedisége csökkent (0,603 → 0,591).
- Az O2 tétel egyedisége tovább nőtt (0,656 → 0,676), töltése -0,531-ről -0,509-re csökkent (jelölt az eltávolításra)
- Az N5 tétel töltése csökkent, egyedisége marginálisan nőtt
- Az O4 töltése jelentősen nőtt (0,577 → 0,652), egyedisége csökkent (0,626 → 0,571)
- Az O5 töltése enyhén csökkent, egyedisége enyhén nőtt
A következő iterációs folyamathoz a jelöltünk az O2 tétel. Eltávolítását követően a mutatóink a következőképpen alakulnak:

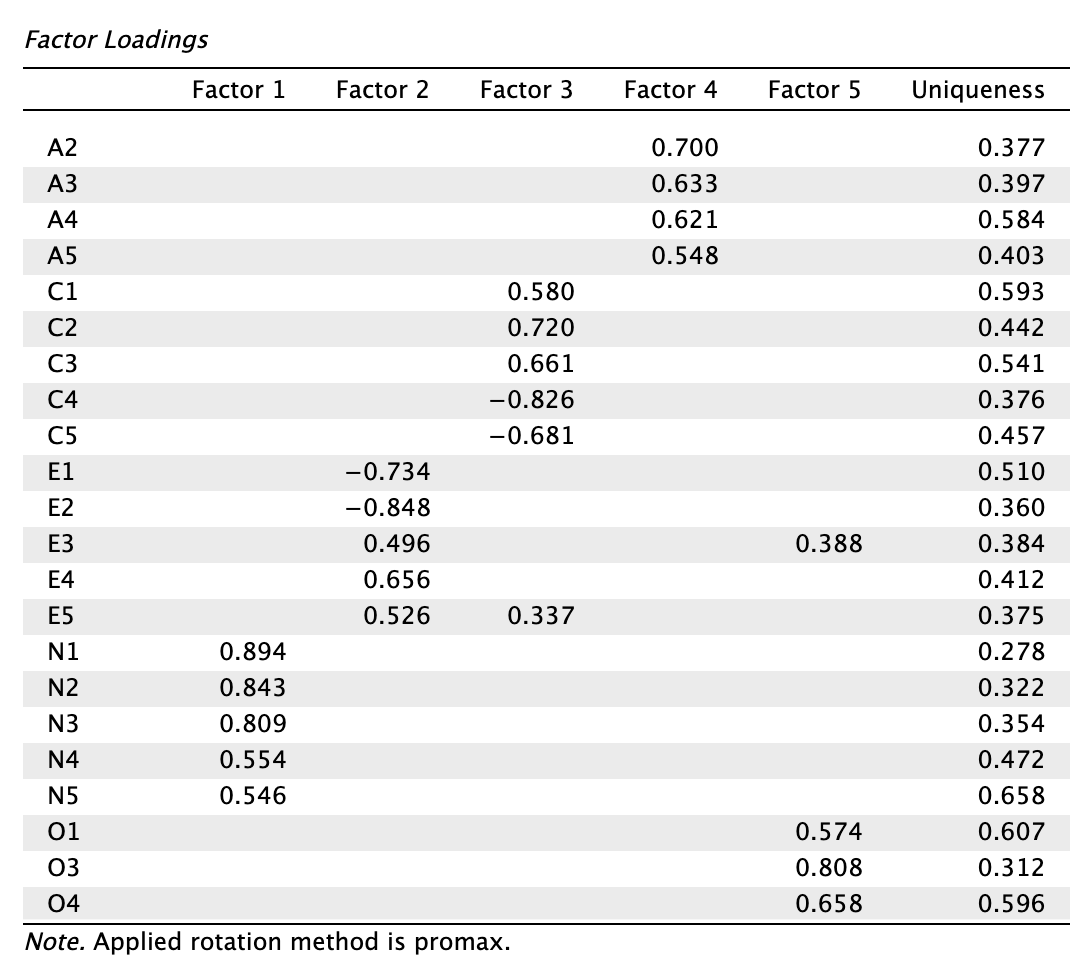
Az láthatjuk, hogy:
- Az RMSEA mutató változatlan: 0,093, 90% CI felső határa: 0,101
- Az SRMR mutató marginálisan javult: 0,037 → 0,036
- A TLI mutató javult: 0,777 → 0,787
- A CFI mutató javult: 0,867 → 0,876
- A BIC mutató romlott: -303,180 → -267,650
- A legnagyobb egyedisége az O5 tételnek van, és drasztikusan emelkedett 0,627-ről 0,692-re, töltése is erősen csökkent -0,589-ről -0,531-re
- Emellett az E3 tétel kereszttöltése magasabb lett, elsődleges töltése alacsonyabb, és a kettő közötti különbség < 0,2.
A következő jelöltünk az eltávolításra az O5 tétel. Eltávolítását követően a mutatóink a következőképpen alakulnak:

Azt láthatjuk, hogy:
- Az RMSEA mutató marginálisan romlott: 0,093 → 0,094, 90% CI felső határa: 0,101 → 0,102
- Az SRMR mutató marginálisan javult: 0,036 → 0,034
- A TLI mutató javult: 0,787 → 0,797
- A CFI mutató javult: 0,876 → 0,886
- A BIC mutató romlott: -267,650 → -234,360
- A Barátságosság töltései javultak, egyedisége az A4 kivételével enyhén csökkent
- A Lelkiismeretesség töltései javultak, egyedisége stabil
- Az Extraverzió töltései átlagosan változatlanok, de az E3 tétel keresztöltés-különbsége romlott
- A Neuroticitás töltései átlagosan javultak, de az N5 tétel egyedisége a legmagasabbra nőtt
- A Nyitottság egyediségei az empirikus küszöb körül alakulnak, ebből a faktorból több tételt kivonni nem lehet.
A következő jelöltünk az eltávolításra az E3 tétel. Eltávolítását követően a mutatóink a következőképpen alakulnak:
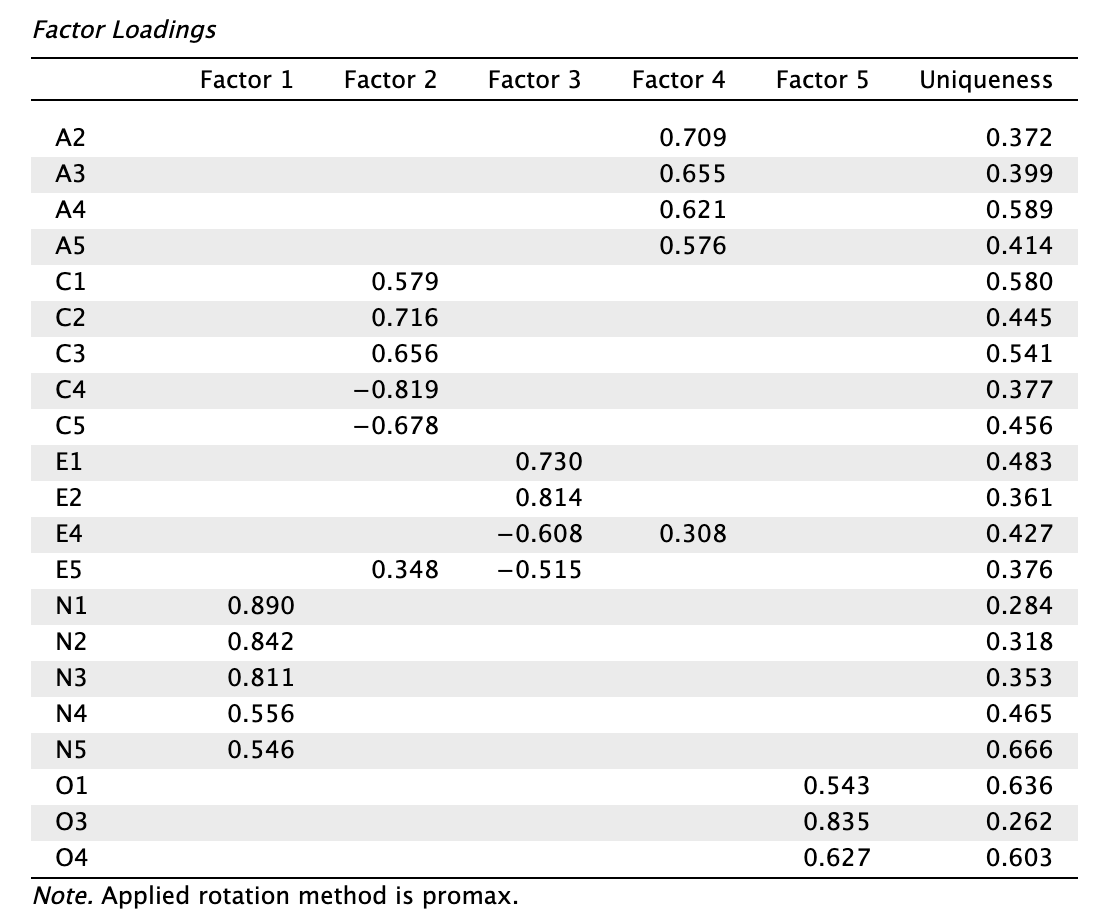

Azt láthatjuk, hogy:
- Az RMSEA mutató marginálisan romlott: 0,094 → 0,095, 90% CI felső határa: 0,102 → 0,104
- Az SRMR mutató stabil: 0,034
- A TLI mutató romlott: 0,797 → 0,791
- A CFI mutató marginálisan javult: 0,886 → 0,887
- A BIC mutató romlott: -234,360 → -192,498
- A Barátságosság töltései javultak, egyedisége stabil
- A Lelkiismeretesség töltései romlottak, egyedisége stabil
- Az Extraverzió töltései romlottak!
- A Neuroticitás töltései stabilak, de az N5 tétel egyedisége a még tovább nőtt
- A Nyitottság egyediségei az empirikus küszöb körül alakulnak, ebből a faktorból több tételt kivonni nem lehet.
Láthatjuk, hogy hibás döntés volt kiemelni az E3 tételt, ezt visszatesszük a modellbe. Próbáljuk kiemelni inkább az N5 tételt helyette.
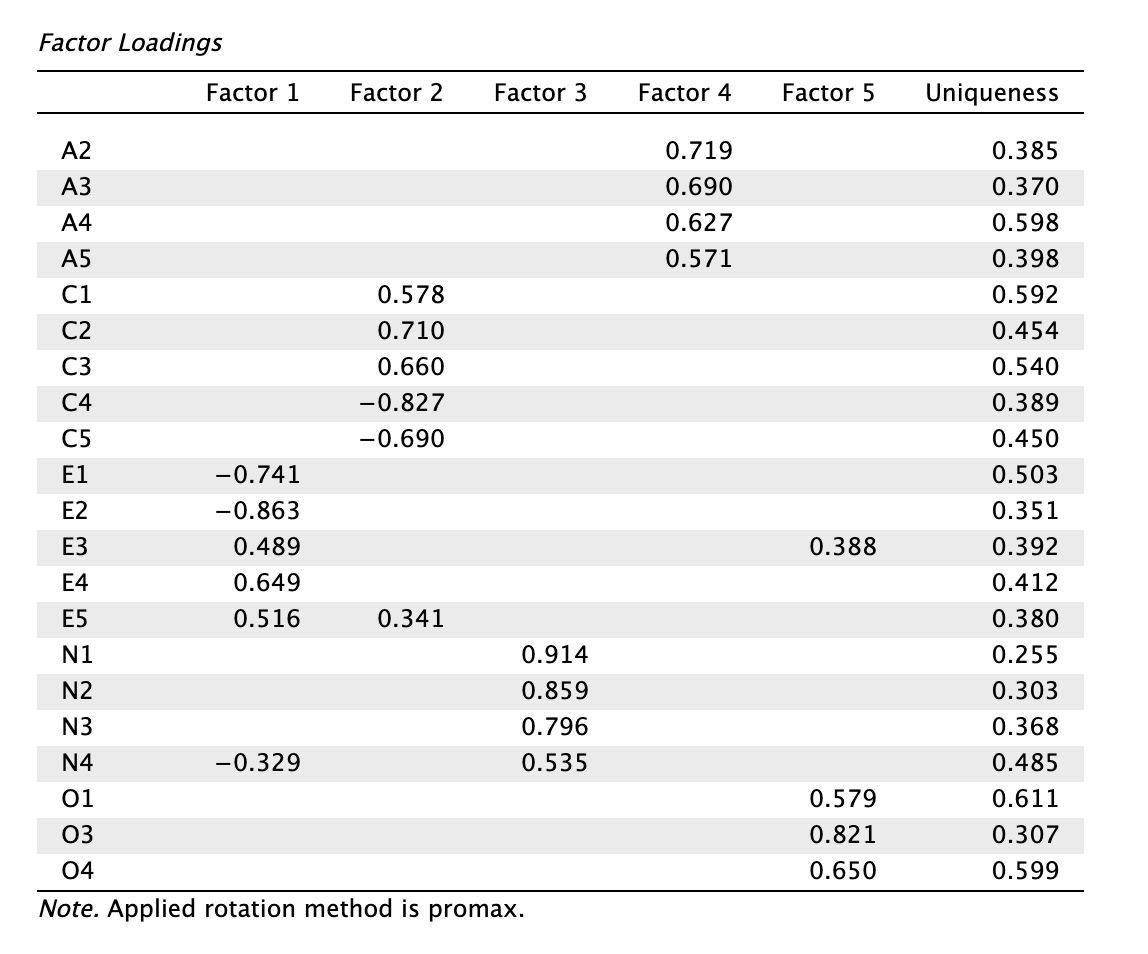

Azt láthatjuk, hogy:
- Az RMSEA mutató marginálisan javult, 90% CI értéke romlott: 0,094 → 0,093, 90% CI felső határa: 0,102 → 0,103
- Az SRMR mutató javult: 0,034 → 0,032
- A TLI mutató javult: 0,797 → 0,808
- A CFI mutató javult: 0,886 → 0,896
- A BIC mutató romlott, de kevésbé: -234,360 → -207,110
- A Barátságosság töltései jelentősen javultak, egyedisége stabil
- A Lelkiismeretesség töltései enyhén romlottak, egyedisége stabil
- Az Extraverzió kereszttöltései rosszabbak, 2 tétel van 0,2-es különbségsávon belül.
- A Neuroticitás töltései stabilak, egyedisége javult
- A Nyitottság egyediségei az empirikus küszöb körül alakulnak, ebből a faktorból több tételt kivonni nem lehet.
Ezt az iteratív folyamatot tovább lehet vinni addig, amíg el nem jutunk egy olyan struktúrához, aminek a mutatói már kedvezőbbek, vagy megállhatunk és jelenthetjük a kapott eredményeket.
Valójában egy noncentralitás alapú inkrementális mutató↩︎
Ettől eltérő értéket kapnánk, ha a korrelációs mátrix lenne kiválasztva.↩︎
Ismerve a Big Five modellel kapcsolatos módszertani problematikákat, nem lepődünk meg, hogy a Nyitottság faktorban van a legtöbb probléma.↩︎
A BIC mutatót nem abszolút értelemben értelmezzük. Két negatív érték közül a kisebb (negatívabb) a jobb.↩︎