19 Megerősítő faktorelemzés (Confirmatory Factor Analysis)
A fejezet megértéséhez a főkomponens-elemzésről és feltáró faktorelemzésről szóló fejezetben tárgyalt variancia, előfeltétel-vizsgálatok, rotáció, töltések és kereszttöltések értelmezése, modellbecslők és modell illeszkedési mutatók ismerete elengedhetetlen.
A megerősítő faktorelemzés (CFA) célja, hogy egy már felállított elméleti modellstruktúra meglétét igazolja a mért adatokon. A feltáró faktorelemzéshez képest ez esetben nem kell rotációval bajlódnunk. Mi magunk mondjuk meg, hogy melyik tétel melyik faktorra tölt, majd a modell illeszkedését, faktortöltéseit és egyéb megfelelőségi mutatóit vizsgáljuk. Valójában forgatást nem tudunk / nem kell választanunk, de azt meg tudjuk jelölni, hogy szerintünk a hipotetikus struktúránk faktorai korrelálnak egymással vagy sem. A pszichológiai kutatásokban szinte mindig fognak.
CFA esetében az egyes faktorokhoz tartozó töltéseket paramétereknek hívjuk.
19.1 Modifikációs indexek
Abban az esetben, ha a feltételezett modell nem illeszkedik jól (pl. RMSEA > 0,08 és CFI < 0,90), meg kell vizsgálnunk, hogy mi lehet az illesztetlenség forrása. Ehhez a modifikációs indexek táblát hívjuk segítségül.
A modifikációs index táblák típusai:
- Maradványkovariancia (Residual covariances): van-e az egyes faktorokat alkotó itemek között maradvány korreláció (faktor által meg nem magyarázott rész).
- Faktorok közötti kereszttöltés (Cross-loading): a főkomponenselemzés és feltáró faktorelmezés során megismert kereszttöltés itt is előfordulhat, hiába rögzítjük mi a struktúrát.
A táblázat tartalmazza a kereszttöltés megjelölését, illetve a kovariáló itempárt, valamint ezek modifikációs indexét és EPC (Expected Parameter Change, paraméter várható változása) mutatóját. Ez utóbbi megmutatja a paraméter töltésében bekövetkező várható változás mértékét és irányát. A modifikációs index pedig azt mutatja meg, hogy milyen mértékben változna a χ2 mutató. A szoftverekben rögzített default 3,84-es küszöbérték arra utal, hogy ekkora küszöbértéknél csökkenne 1-gyel a χ2 szabadságfoka. Ennél alacsonyabb megjelenítési küszöbértéket is használhatunk.
A modifikációs táblákban megjelölt értékek alapján rögzíthetünk a modellünkben például itemek között mindenképpen visszamaradó kovarianciát, azonban ezt csak akkor tehetjük, ha erős, előzetes (a priori) tudásunk, meggyőződésünk alapján tesszük, nem pedig matematikai „szépítések” okán.
19.2 Faktorok által kifejezett átlagos variancia (Average Variance Extracted)
Az AVE azt mutatja meg, hogy adott faktor mekkora hányadát magyarázza meg a hozzá tartozó itemek varianciájának, vagyis a mért változók mennyire konvergálnak a látens fogalom körül.
\[ \text{AVE} = \frac{\sum{\text{standardizált faktortöltés}^2}}{\sum{\text{standardizált faktortöltés}^2} + \sum{\text{standardizált maradékvariancia}}} \]
Általános szabály szerint a 0,5 feletti érték számít jónak (Fornell és Larcker, 1981), vagyis a mérési hiba kisebb, mint a faktor által magyarázott variancia.
A diszkrimináns validitás egyik ellenőrzésére is használhatjuk az AVE mutatót. A Fornell-Larcker kritérium szerint egy faktorhoz tartozó \(\sqrt{\text{AVE}}\) értéknek nagyobbnak kell lennie, mint a vizsgált faktor és a többi faktor közötti korreláció.
19.3 Heterotrait-monotrait ratio (HTMT)
A diszkrimináns validitás egyik legfrissebb, legmodernebb vizsgálati eszköze a heterotrait-monotrait arány (Henseler és mtsai., 2015). Ennél még újabb mutatószám a HTMT2 (Roemer és mtsai., 2021), ami a HTMT számítását annyiban módosítja, hogy a korrelációk átlagolására nem számtani, hanem mértani átlagot alkalmaz.
A JASP a semTools::htmt() funkcióját alkalmazza, amiben a default beállítás a htmt2 = TRUE, tehát a JASP frissebb változatai által megjelenített HTMT mutatószám a mértani átlagot használó HTMT2 mutató.
Jó diszkrimináns validitást jelent a < 0,85 érték, de a 0,90-nél nagyobb érték a diszkrimináns validitás hiányára utal.
19.4 Tétel-invarianciák mérésének eszközei: Multiple-group CFA (MGCFA) és Differential Item Functioning (DIF)
A pszichometriai munkában igazolnunk kell, hogy egyes csoportosító változók mentén az egyes itemek hasonlóképp működnek és nem térnek el, nem mérnek másképp (Differential Item Functioning, differenciáló tételműködés). Például egy tudásszintet vizsgáló kérdőív másképp működik-e nemek szerinti, vagy kultúrák szerinti bontásban. A DIF-elemzés a beépített torzítást szűri ki. A cél, hogy a teszten mért különbségek ne a tételek hibájából, hanem képességbeli különbségekből adódjanak.
A megerősítő faktoranalízisben erre használt eszköz a többcsoportos megerősítő faktorelemzés (Multiple-group CFA).
Ennek ellenőrzését hierarchikusan az alábbi módokon, szinteken vizsgálhatjuk:
- modellkonfigurációs invariancia (configural invariance): csoportosító változónként azonos a faktorstruktúra
- metrikus invariancia (metric invariance) (gyenge): a faktortöltéseket azonosak csoportonként
- skálainvariancia (scalar invariance) (erős): a faktortöltéseken felül az itemek interceptje (mérési egyenleg konstans tagjait) is azonos
- szigorú invariancia (strict): az itemek közötti hibatagok, egyedi varianciák is megegyeznek a fentieken túl
A gyakorlatban úgy vizsgáljuk, hogy a JASP-ban beállítjuk a csoportosító változót, az invariancia mérési szintjét (configural — strict), és a frissített modellillesztési mutatókat összevetjük a csoportosítás nélküli, nyers modellillesztési mutatókkal.
A gyakorlatban a skálainvariancia megléte kritikus ahhoz, hogy a csoportok közötti látens átlagokat összehasonlíthassuk.
19.5 Paraméterek standardizálása
A faktortöltéseket, paramétereket standardizálni szoktuk, ez könnyíti meg az értelmezést és összehasonlíthatóságot.
A standardizálás szintjei a statisztikai szoftverekben:
- None: Nincs standardizálás, a modell becslése az eredeti skálákon történik. A skála rögzítése (identification) során i) vagy az első item (marker variable) töltését, ii) vagy a látens faktorok varianciáját rögzítjük 1,000-n.
- Latents: Csak a faktorokat (látens változókat) standardizáljuk (SD = 1), a mért (manifeszt) itemeket nem, ők megtartják az eredeti mértékegységüket. A töltések azt mutatják, mennyit változik az item értéke, ha a látens faktor 1 szórásnyit nő.
- All: Mind a látens, mind a mért változókat standardizáljuk, ilyenkor a faktortöltések korrelációként (r) értelmezhetőek, értékük −1 és 1 közé esik.
Konvergens validitáshoz az All típusú standardizálás során kiszámított |0,7| fölötti standardizált értékek ideálisak, mert ennél a szintnél az item a variancia kb. 50%-át magyarázza \(0{,}7^2 = 0{,}49\). Ha az AVE eléri a 0,5-t, akkor a gyakorlatban elegendő |0,5| fölötti standardizált érték is a konvergens validitáshoz.
19.6 Példák megerősítő faktorelemzésre
Példa 19.1 A Mini Oldenburg Kérdőív (MOLBI) magyar változatának (Ádám és mtsai., 2020) validálását végezzük a saját mintánkon (N = 400). A kérdőív 10 tételből áll, 4 fokú Likert skálán kell értékelni az állításokat. Két skálával rendelkezik, és a megjelölt tételekből tevődik össze (F – fordított tétel):
- kiábrándultság: 1, 3(F), 6(F), 7(F), 10
- kimerülés: 2(F), 4(F), 5, 8, 9(F)
Magasabb érték nagyobb mértékű kiégésszintet indikál.
A magyar validálás alapján tudjuk, hogy a két faktor között magas a korreláció egészségügyi mintán (r = 0,81), heterogén mintán alacsonyabb (r = 0,49). A kimerültség alskála 16%-át magyarázza a teljes varianciának, a kiábrándultság alskála esetén ez 47%. Bifaktor modellben elrendezve az általános kiégés faktor 66%-át magyarázza a varianciának.
A validáláshoz robusztus ML módszert (MLR) használtak a kutatók az egészségügyi mintán. A MOLBI kimerülés faktorhoz tartozó standardizált töltések 0,469-0,765 között mozogtak, míg a kiábrándultság faktorhoz tartozók 0,224-0,779 között. Legalacsonyabb, 0,3 alatti faktortöltése a 10. tételnek volt. A modellilleszkedési mutatók az egészségügyi mintán: Satorra—Bentler-korrigált χ2 (34) = 85,716, p < 0,001, CFI = 0,928, TLI = 0,905, RMSEA = 0,076 [0,056-0,096], SRMR = 0,059.
Az adatfájl letölthető: miniold_mg.sav
Állítsuk be a vizsgálatot JASP-ban:
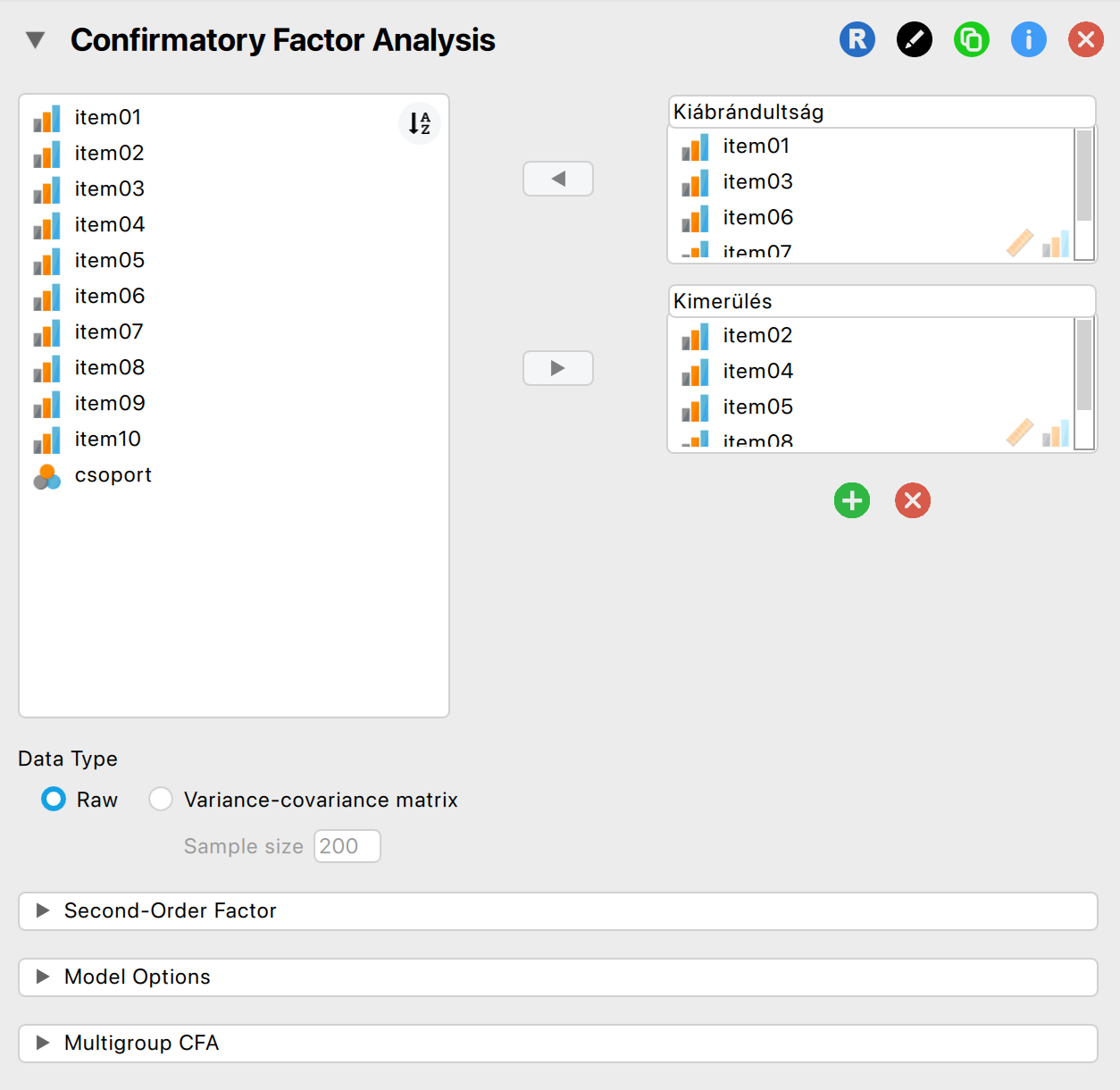
- Hozzuk létre a faktorokat a Confirmatory Factor Analysis modulban, ezeket elnevezhetjük a könnyebb értelmezés érdekében.
- Jelenítsük meg az Additional Output rovatot és mindenképpen jelenítsük meg
- az előfeltételvizsgálatokat: Kaiser-Meyer–Olkin (KMO) test, Bartlett’s test of sphericity;
- a modellilleszkedési mutatókat (χ2-en felül): Additional fit measures;
- az item által magyarázott varianciákat (R-Squared);
- a faktorok által kifejezett átlagos varianciát (Average variance extracted (AVE));
- Heterotrait–monotrait ratio (HTMT) mutatókat;
- maradvány kovarianciát: Residual covariance matrix;
- modifikációs indexet: Modification indices
- Rajzoltassuk meg a modell ábráját (Model plot), azon belül ábrázoltassuk a standardizált paraméterbecsléseket (Show parameter estimates, Standardized), és a visszamaradt varianciát (Show variances).
- A modellbecslési paramétereket és egyéb beállításokat:
- A modellbecslő függvényt az Estimator rovatban válasszuk ki. Az eredeti cikk MLR (Maximum Likelihood Robust) módszert választott. Mi használjuk 4-fokú likert skála (alacsony fokú, nem normál, ordinális) okán a WLSMV módszert!
- A paraméterstandardizálást állítsuk None-ról All opcióra!
- A hiányzó adatok kezelésére használjuk a defaultként beállított Listwise deletion módot.
- Olvassuk le az előfeltétel-vizsgálatok eredményeit!
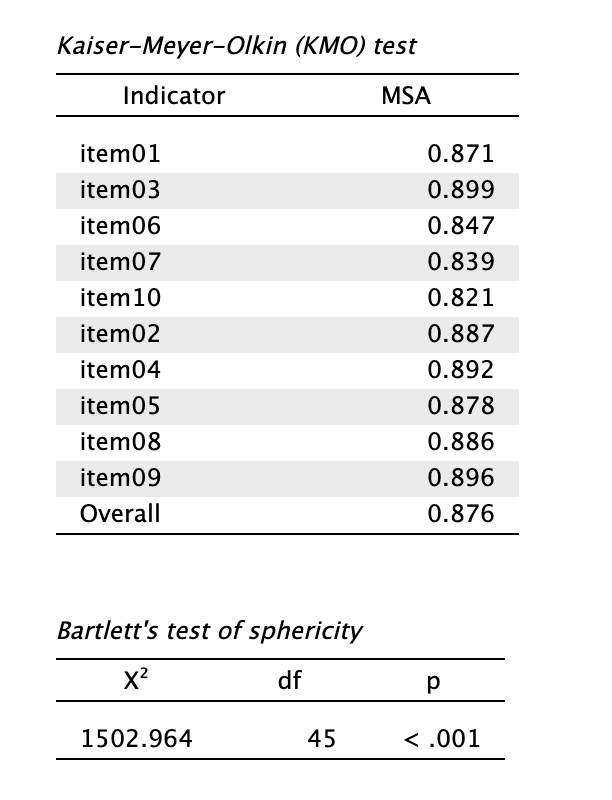
Láthatjuk, hogy mind a teljes adatkészletre (Overall KMO), mind az egyedi itemekre vonatkozó (MSA) értékek nagyon magasak. Továbbá a Bartlett-féle szférikusság próba szignifikanciája jelzi, hogy az adatok valóban faktorálhatók.
- Olvassuk le a modellerősségi mutatókat!
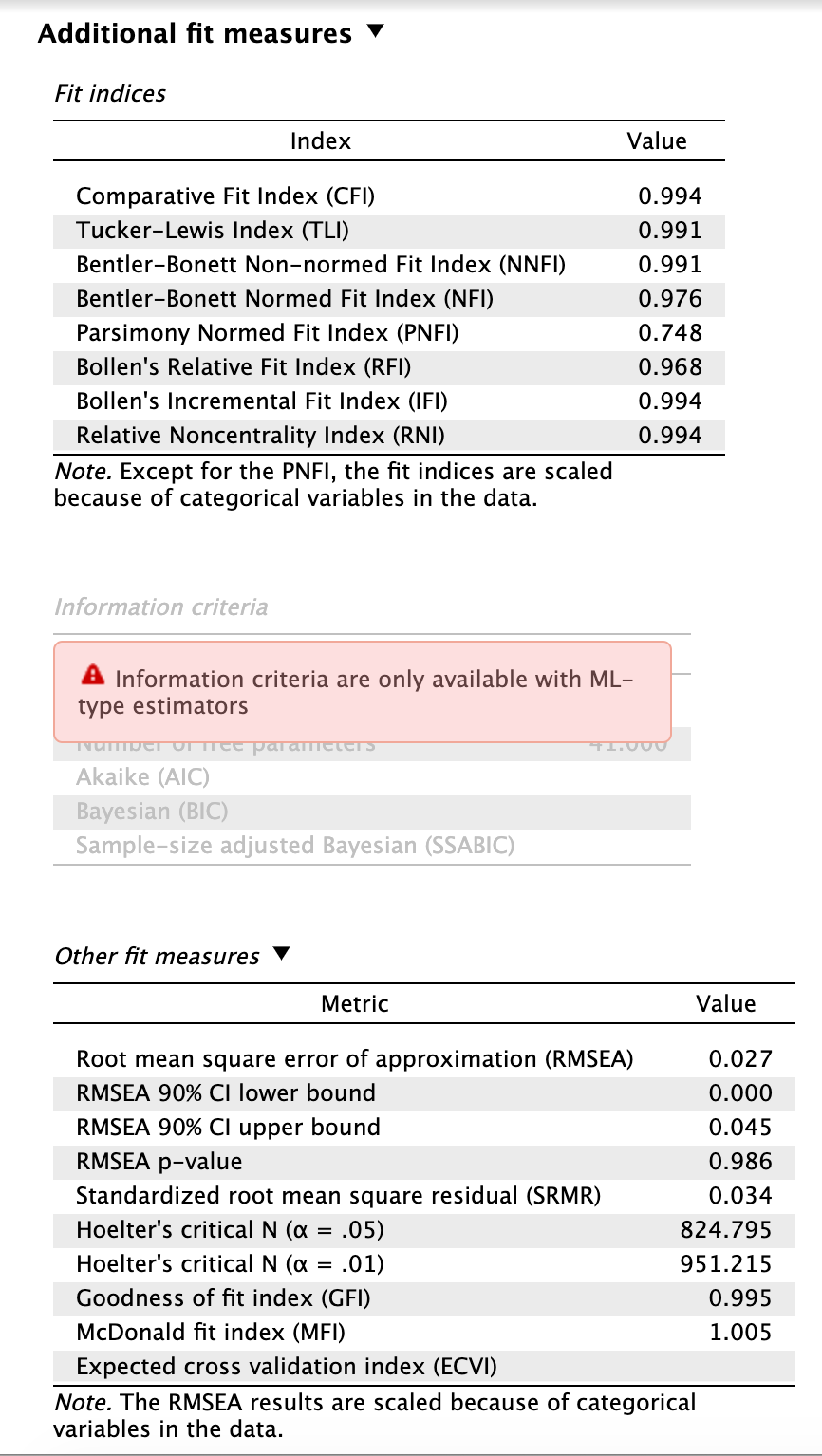
Számunkra a legfőbb mutatók az RMSEA, RMSEA 90% CI felső értéke, SRMR, CFI és TLI mutatók. Ezek a validációs cikkben is szereplő egyes mutatók. Értelmezzük ezeket!
Megközelítési négyzetes középérték hiba, RMSEA: 0,027 [90% CI: 0,000-0,045]
- RMSEA érték ideálisan ≤ 0,06 (Hu és Bentler, 1999), < 0,08 elfogadható (Browne és Cudeck, 1992)
- 90% CI felső érték: 0,045, ideálisan 0,10 alatt van
Standardizált reziduális négyzetes középérték, SRMR: 0,034 ≤ 0,08 (Hu és Bentler, 1999)
Összehasonlító illeszkedés mutató, CFI: 0,994 > 0,95 (Hu és Bentler, 1999)
Tucker-Lewis Index, TLI: 0,991 > 0,95
A cikk említi emelett a χ2/df mutatót is. Ennek a referenciaértéke < 2 alatt kiváló (Cole, 1987), < 5 alatt elfogadható (Wheaton és mtsai., 1977). Ezt az alábbi táblából leolvasva számítjuk ki (a Factor modell értékeit leolvasva):

\[ \frac{\chi^2}{\text{df}} = \frac{46{,}176}{34} = 1{,}358 < 2 \]
- Olvassuk le a standardizált paramétereket és kapcsolódó értékeket
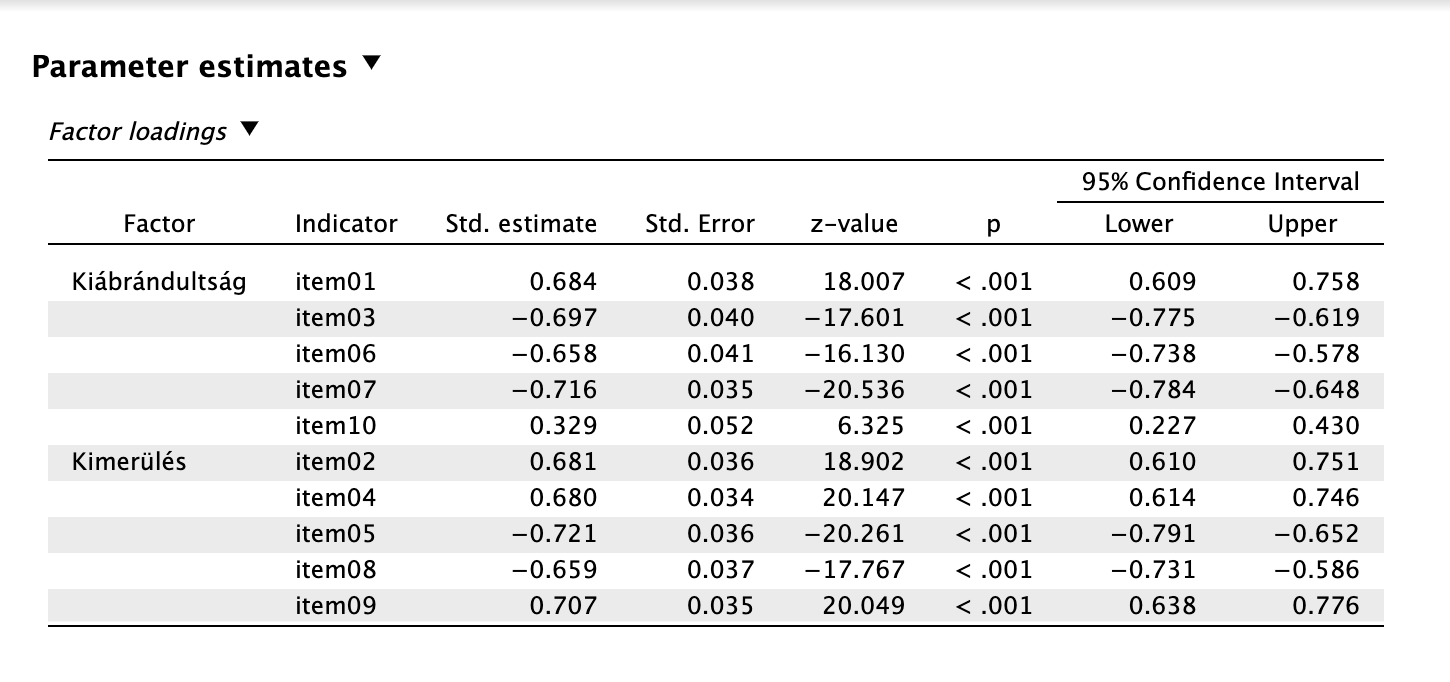
Láthatjuk, hogy mindegyik paraméter szignifikáns (z-érték melletti p-érték). Abszolút értékük a kiábrándultság faktor esetén 0,329 (item 10) és (-)0,716 (item 7) közé, kimerülés faktor esetén (-)0,659 (item 8) és (-)0,721 (item 5) közé esik. Észrevehetjük, hogy a 10. tétel töltése a mi mintánkban is kritikusan alacsony.

Láthatjuk, hogy a faktorok közötti standardizált kovariancia (ami effektíve korreláció) értéke -0,598, és ez szignifikáns (p < 0,001). Mivel ez bőven meghaladja a 0,3-as értéket (ami azért nem ökölszabályszerű cutoff), indokolt feltételezni a faktorok korreláltságát.
(Az eredeti cikkekben r = 0,81, illetve 0,49 a korreláció a faktorok között. A mi adatainkban ez -0,598. Ennek oka technikai: a tételek nyersen szerepelnek, nincsenek megfordítva, és a marker változók iránya számít a paramétertöltések között. Tehát az 1. item normál, míg a 3, 6, 7 fordított [a 10 túl kicsi, nem számít annyira], így a kiábrándultság faktor logikája a marker item + töltése miatt: magasabb pontszám → nagyobb kiábrándultság. A kimerülés faktorban viszont a marker változónk fordított tétel, de mi nem fordítottuk meg, nyersen hagytuk, ezért itt a logika: magas pontszám → alacsony kimerülést jelent. Tehát értelemszerűen a két látens faktor a marker változók iránya miatt negatív korrelációt mutat, de ettől még nem mond ellent a cikknek, sőt, megegyezik vele.)
- Olvassuk le a konvergens és diszkrimináns validitás mutatóit!
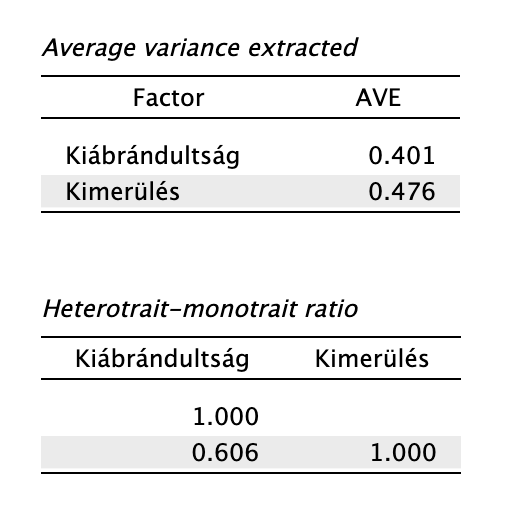
Az AVE táblázat alapján a kiábrándultság faktor által megmagyarázott variancia 0,401, míg a kimerülésé 0,476. Mivel mindkét érték elmarad az elvárt 0,5-ös küszöbértéktől, a skála konvergens validitása ezen a mintán nem éri el az optimális szintet. Ez a gyakorlatban azt jelenti, hogy a tételekben lévő mérési hiba nagyobb, mint a látens faktorok által megmagyarázott variancia.
A HTMT értéke 0,606, ami lényegesen kisebb, mint a kritikus 0,85-ös határéték, a diszkrimináns validitás megfelelő, tehát a két faktor – bár korrelál – érdemben elkülönül egymástól.
- Vizsgáljuk meg a modifikációs indexeket!
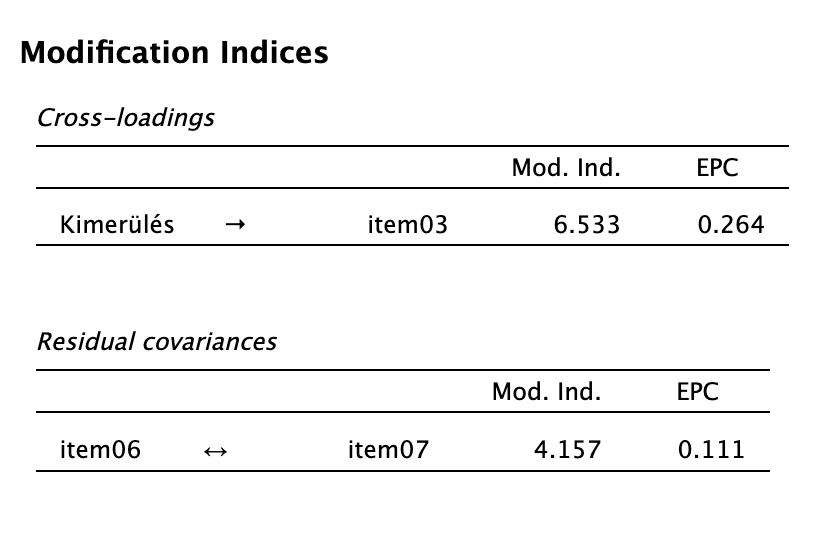
A modifikációs indexek kereszttöltésre vonatkozó táblázata szerint a kimerülés faktorra a 3-as tétel 6,533-as módosító indexszel (MI) rendelkezik. A maradvány kovarianciára vonatkozó táblázatban pedig azt látjuk, hogy a 6-os és 7-es tételek közötti MI 4,157.
Pusztán statisztikai alapon – erős elméleti megalapozottság nélkül – nem építjük be ezeket a modellünkbe (nem szabadítjuk fel őket).
- Olvassuk le a maradványvarianciákat és az R2 értékeket!
A modell kiértékelésekor fontos megvizsgálnunk, hogy az egyes itemek varianciáját milyen mértékben magyarázzák a látens faktorok, és mekkora a fennmaradó hiba.
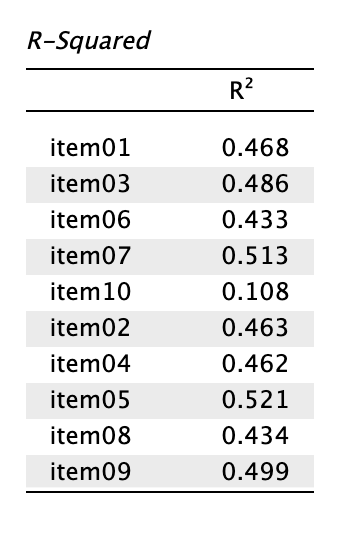
R2: Az item varianciájának azt a részét mutatja, amelyet a hozzárendelt látens faktor megmagyaráz. Az adatainkban 0,433 és 0,521 között mozog, kivéve a 10. item esetén, ami kritikusan alacsony (0,108, tehát 10,8%-ot magyaráz).
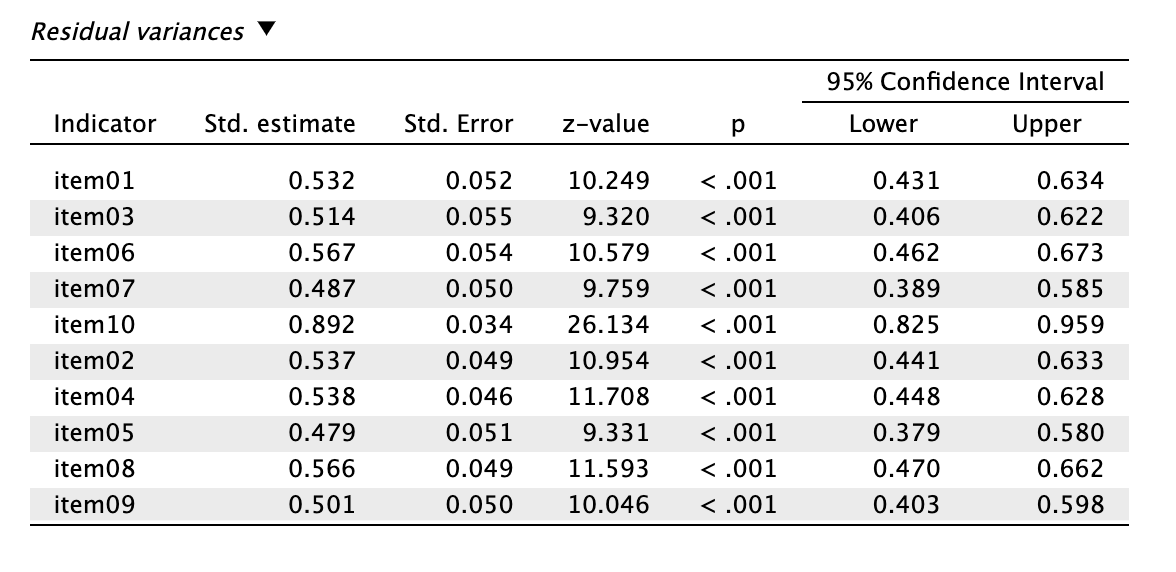
Residual Variances tábla: A mérési hibát és a faktor által meg nem magyarázott egyedi varianciát jelöli, vagyis a maradványvarianciát. A 10. tétel maradványvarianciája kiugróan magas (0,892), ami nem meglepő ilyen alacsony faktortöltéssel és R2 értékkel. A többi item maradványértéke 0,479 és 0,567 között alakul.
- Ábrázoljuk a modellt!
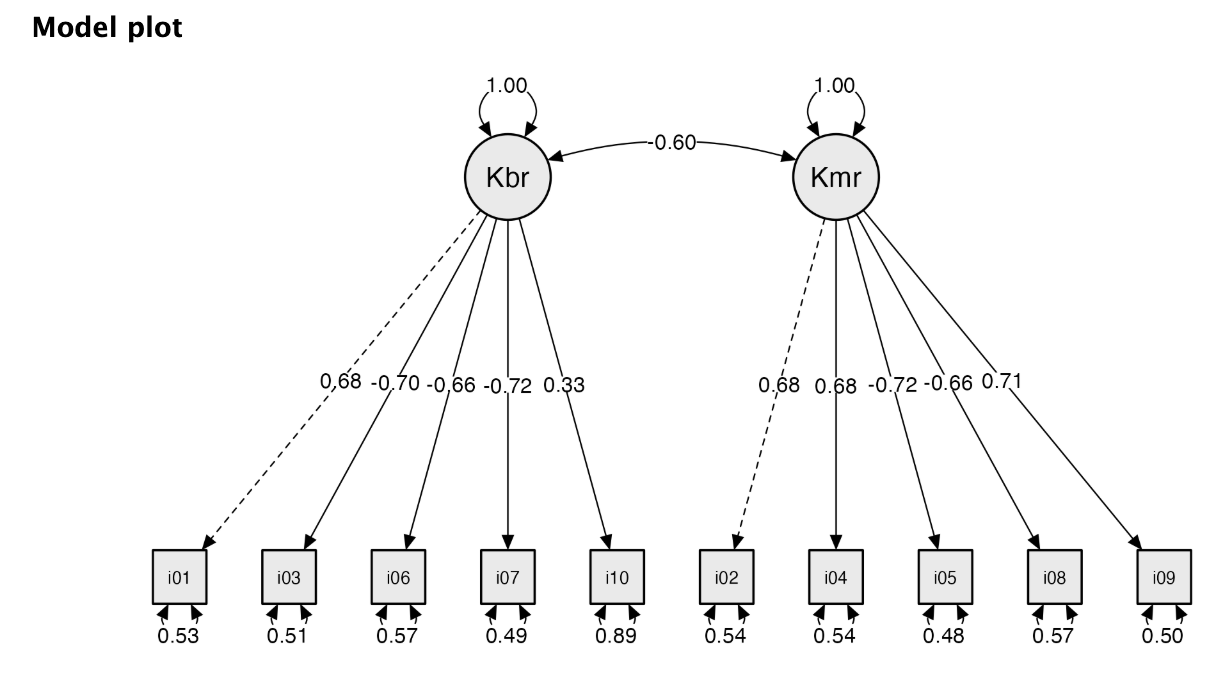
A körökben ábrázol Kbr és Kmr a faktorainkat jelölik rövidítve. Köztük kétirányú nyíl van, ami a már fentebb leírt faktorok közötti korrelációt jelöli 2 tizedesjeggyel.
A standardizált faktortöltések a látens faktorokból a négyzettel jelölt itemek felé kiinduló nyilakon szerepelnek.
A legutoljára vizsgált hibatagokat (maradványértékeket, maradványvarianciát) a négyzetek alatti nyilakon szereplő értékek mutatják.
A szaggatott vonalak a referencia-indikátorokat (marker változókat) jelölik. A faktoroknak nincs saját mértékegysége, ezért kijelölünk (identifikálunk) egy változót, aminek a mértékegységét felveszik. Alapértelmezés, hogy az első, faktorhoz behúzott változót használja a szoftver (ezért ha nem standardizálunk, ennek a paraméterértéke 1,000).
- Mit kezdünk a gyakorlatban a 10. tétellel?
Két opciónk van:
- kitöröljük a modellből az alacsony töltés, alacsony R2 és magas maradványvariancia miatt, hogy ezáltal javítsuk a konvergens validitásunkat
- a skála integritása miatt bent hagyjuk és lejlentjük így
A példa kedvéért most a skála integritását preferáljuk (ahogy a többi kutató is tette).
Megoldás 19.1. (Módszerek részben fel kell tüntetni, hogy mi alapján értékeljük a modellilleszkedési mutatókat, pl. nálunk Hu és Bentler, 1999.)
A Mini Oldenburg Kérdőív (MOLBI) elméleti, kétfaktoros (Kiábrándultság és Kimerülés) modelljét megerősítő faktorelemzéssel kívántuk igazolni a mintánkon. Első lépésben ellenőriztük az adatmátrix faktorálhatóságát. A Kaiser-Meyer-Olkin (KMO) mutató értéke 0,876 volt, az egyedi MSA értékek pedig minden tétel esetén meghaladták a 0,8-s „dicséretes” szintet, ami alapján az adatok megfelelőek a faktoranalízishez. A Bartlett-féle szfericitási próba szignifikáns eredményt hozott (χ2(45) = 1502,96, p < 0,001), tehát a tételek közötti korrelációk alkalmasak a látens struktúra feltárására és megerősítésére.
A kétfaktoros modellt robusztus WLSMV becslési eljárással vizsgáltuk, különös tekintettel a tételek ordinális mérési szintjére és a pszichometriai szakmai ajánlásokra. A modellilleszkedési mutatók megfelelőek, kiváló illeszkedést jeleztek: χ2(34) = 46,18, p = 0,079; χ2/df = 1,36 (< 2); CFI = 0,994 (> 0,95); TLI = 0,991 (> 0,95); RMSEA = 0,027 (≤ 0,06) [90% CI: 0,000-0,045 (< 0,10)]; SRMR = 0,034 (≤ 0,08). [Ezeket táblázatban is feltüntethetjük folyó szöveg helyett, de az értékelést, miszerint megfelelőek, le kell írnunk szövegesen, és a táblázatban szerepeltetnünk illik a zárójelben megadott kritériumokat is!]
A standardizált faktortöltések minden tétel esetében szignifikánsak voltak (p < 0,0011). A Kiábrándultság faktoron a töltések 0,329 és 0,716, a Kimerülés faktoron 0,659 és 0,721 között mozogtak abszolút értékben.
A faktorok által kifejezett átlagos variancia (AVE) a Kiábrándultság (AVE = 0,401) és a Kimerülés (AVE = 0,476) dimenzió esetén is elmaradt az elvárt 0,5-ös szinttől, így a konvergens validitás gyengébb az elvártnál. [A kiváló illeszkedés (CFI, RMSEA stb.) alapján a modell szerkezete helyes, de az alacsony AVE értékből arra következtethetünk, hogy az egyedi tételek zajosabbak az ideálisnál. - Ez a mondat is mehet a Diszkusszióba, mert értékel.] A diszkrimináns validitás megfelelő, mert az ennek ellenőrzésére használt HTMT arány 0,606, ami a 0,85-ös határérték alatt van.
A két látens faktor közötti standardizált kovariancia (korreláció) értéke r = −0,598, p < 0,001 volt, tehát ez igazolja, hogy a faktorok nem korrelálatlanok (r > 0,3). A korrelációs együttható negatív előjele csupán a fordított tételek nyersadatként történő kezelésének melléktermékei: a valós, mögöttes együttjárás a konstruktumok között azonos irányú, pozitív.
A modifikációs indexek alapján javasolt lett volna paraméterfelaszabadítás mind a kereszttöltés (3. tétel, kimerülés faktor), mind a maradványkovariancia (item 6 és 7) szempontjából, ezeknek nem volt előzetes elméleti megalapozottsága, a modellilleszkedés pedig kiváló. A maradványvarianciák a 10. tételt (0,892) kivéve 0,479 és 0,567 között alakultak, ami megfelelő.
Hasonlóan a magyar validációs cikkben (Ádám és mtsai., 2020) közölt eredményekhez, a 10. item töltése (0,329) és magyarázott varianciája (R2 = 0,108) ezen a mintán is nagyon alacsony volt, míg reziduális varianciája magas. Ez is oka lehet az alacsonyabb konvergens validitásnak. [A 10. tételre vonatkozó mutatókat érdemes kiemelni mindenképpen szövegesen. A konvergens validitásra vonatkozó értékelő mondat helye lehet a diszkusszióban inkább, mivel értékelő állítás, illetve feltételezés.] A kérdőív integritását priorizáltuk, így a 10. tételt nem vettük ki a modellből, mert ezzel együtt is kiváló modellilleszkedést mértünk.
Itt azért írtunk p < 0,001 értéket, mert minden értékünk ennyi lett, nem pedig azért, mert 0,1%-os α szint mellett értékelnénk a szignifikanciát. Az továbbra is α = 0,05. Tehát írhatnánk azt is, hogy p < 0,05, ezzel azt jelölnénk, hogy ez volt a szignifikanciaküszöbünk↩︎