17 Főkomponens-elemzés
A főkomponens-elemzés (PCA, principal component analysis) egy dimenziócsökkentő adatelemzési eljárás, egy adatredukciós technika, az adatmátrix változóinak csökkentésének egyik technikája. Célja, hogy több, egymással korreláló változóból álló adathalmazt kisebb, egymással nem korreláló főkomponenseket (változókat) hozzon létre.
A főkomponensek a ténylegesen mért változók lineáris kombinációja, pusztán matematikai redukció, nem feltételezünk látens, oksági struktúrát.
A cél, hogy a lehető legkevesebb komponenst hozzuk létre, miközben a lehető legkisebb az információveszteség.
A változók varianciája
Egy változó teljes varianciája három részre bontható forrásai szerint:
közös variancia (kommunalitás) más változókkal, \(h^2\),
egyedi variancia, \(1-h^2\), amely tovább bontható:
- specifikus varianciára és
- hibára.
A teljes variancia tulajdonképpen az emberek válaszai közötti különbségek összessége. Ha mindenki ugyanazt válaszolná a kérdőívre, a variancia 0 lenne.
A főkomponens-elemzés nem tesz különbséget a variancia forrásai között. Mind a specifikus varianciát, mind a mérési hibát együttesen kezeli a közös varianciával. Egész pontosan főkomponens-elemzés során abból a feltételezésből indulunk ki, hogy h2= 1, vagyis 100% a kommunalitás, a teljes varianciában nincs egyedi variancia.
A főkomponenselemzés szükségessége
Főkomponens-elemzést akkor célszerű használnunk, amikor prediktív modellezéshez sok, egymással korreláló változót egy-két változóba akarunk sűríteni, például többszörös lineáris regressziós elemzés során a multikollinearitás megoldására hívhatjuk segítségül. Ha azt vizsgáljuk, hogy egy kardiovaszkuláris esemény (pl. szívinfarktus) után a beteg mennyire működik együtt a kognitív viselkedésterápiás intervencióval, és a mért változók (pl. depresszió, szorongás, stressz, szomatizáció) klinikailag és statisztikailag is erősen korrelálnak, multikollinearitás állhat fenn, amitől instabil lesz a regressziós modellünk. Megoldás lehet a változókon végrehajtott főkomponens-elemzés, ami egy főkomponenst eredményez (amit elnevezhetünk pl. általános distressznek), így a négy változó helyett ezt az egy komponenst visszük be a lineáris regressziós modellünkbe, ami így már stabilabb.
Másik példa lehet, ha terápiás hatékonyságot mérünk affektusregulációs biofeedback adatokkal (pl. szívfrekvencia-variábilitás [HRV], bőrellenállás, szérum kortizolszint), a három élettani változóból képzehetünk egy fizológiai arousal nevű főkomponenst, és ezt használjuk később a statisztikai próbákban (ezáltal korlátozva az elsőfajú hiba mértékét, nem úgy, mintha a három változón külön-külön futtatnánk elemzéseket).
Ha a célunk a pszichológiai konstruktumok feltárása és megértése, a főkomponens-elemzés torzíthat, mert a mérési hiba is beépül a számításba. Ezzel szemben a faktorelemzés sokkal tisztább képet ad, ezért is ez a preferált módszer a pszichometriában az elméleti struktúra feltárására.
17.1 A főkomponens-elemzés generikus lépései
A főkomponens-elemzés lépései egyszerűsítve a következők a pszichológiai kutatásokban:
A mért adatokból korrelációs mátrixot, kovariancia-mátrixot (Σ) vagy polikorikus korrelációs mátrixot hozunk létre.
Kovariancia-mátrix esetén a nagyobb varianciával rendelkező tételek fognak „dominálni”. Ezt elkerülendő, standardizálhatjuk a változókat (pl. z-transzformációval), vagy használhatunk korrelációs mátrixot.
Korrelációs mátrix esetén a változókat valójában standardizáljuk is. Mindenképp célszerű korrelációs mátrix alapú PCA-t választani, ha a redukálandó adatok mértékegységei / skálái nem azonosak.
Polikorikus korrelációs mátrixot ordinális adatoknál, kimondottan Likert tételeknél használunk (Kiwanuka és mtsai., 2022). Mindenképpen ezt kell válasszuk, ha a Mardia mutatók (ld. előfelétel-vizsgálatok) szignifikánsak, mert a Pearson-féle korrelációs mátrixok alábecsülnék a valódi kapcsolatot a tételek között (Garrido és mtsai., 2013).
Megkeressük azt a lineáris kombinációt (első főkomponenst, PC1), amely mentén az adatok varianciája a legnagyobb. Ez matematikailag a kovarianciamátrix legnagyobb sajátértékéhez (eigenvalue, λ1) tartozó sajátvektor (eigenvektor, v1).
Ezután megkeressük a második főkomponenst (PC2), ami a maradék varianciát maximalizálja azzal a feltétellel, hogy merőleges (ortogonális) az első főkomponensre. Matematikailag ez a második legnagyobb sajátértékhez tartozó sajátvektor.
Ha van még meg nem magyarázott variancia, újabb főkomponenst hozunk létre.
Meghatározottuk az összes megtartandó főkomponens számát egyes kritériumok mentén.
Főkomponens-elemzést végzünk 5 tétellel:
- V1: Nagyon zaklatott vagyok
- V2: Semmi nem érdekel többé
- V3: Feszült lelkiállapotban vagyok
- V4: Nem hiszem, hogy értékes ember vagyok
- V5: Semmiben nem találok élvezetet
Főkomponens-elemzést végezve azt feltételezzük, hogy nincs mérési hiba és nincsenek egyedi varianciák. Létrehozunk a felvett adatokból egy korrelációs mátrixot:
| V1 | V2 | V3 | V4 | V5 | |
|---|---|---|---|---|---|
| V1 | 1.00 | ||||
| V2 | 0.21 | 1.00 | |||
| V3 | 0.85 | 0.19 | 1.00 | ||
| V4 | 0.19 | 0.75 | 0.27 | 1.00 | |
| V5 | 0.31 | 0.80 | 0.26 | 0.85 | 1.00 |
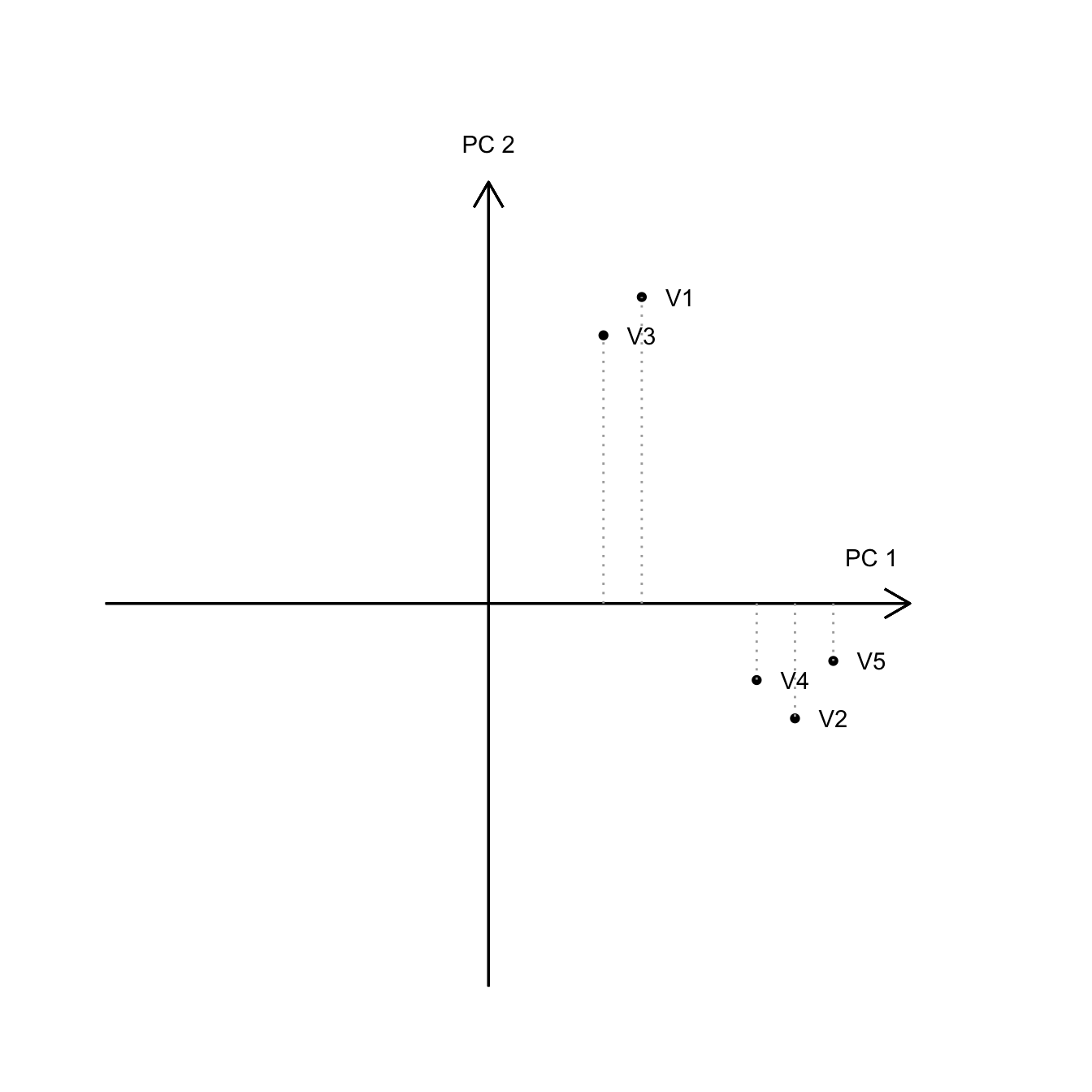
Kiszámítjuk és ábrázoljuk a főkomponenseket. Láthatjuk, hogy melyik item, melyik főkomponensre tölt:
- V3 és V1 tételek lényegesen gyengébben töltenek az 1. főkomponensre, mint a V4, V2, V5
- Hasonlóképpen V1 és V3 tételek töltenek a legerősebben a 2. főkomponensre, míg a V5, V4, V2 a leggyengébben
Az alábbi videókban a főkomponens-elemzést magyarázzák el lépésről lépésre:
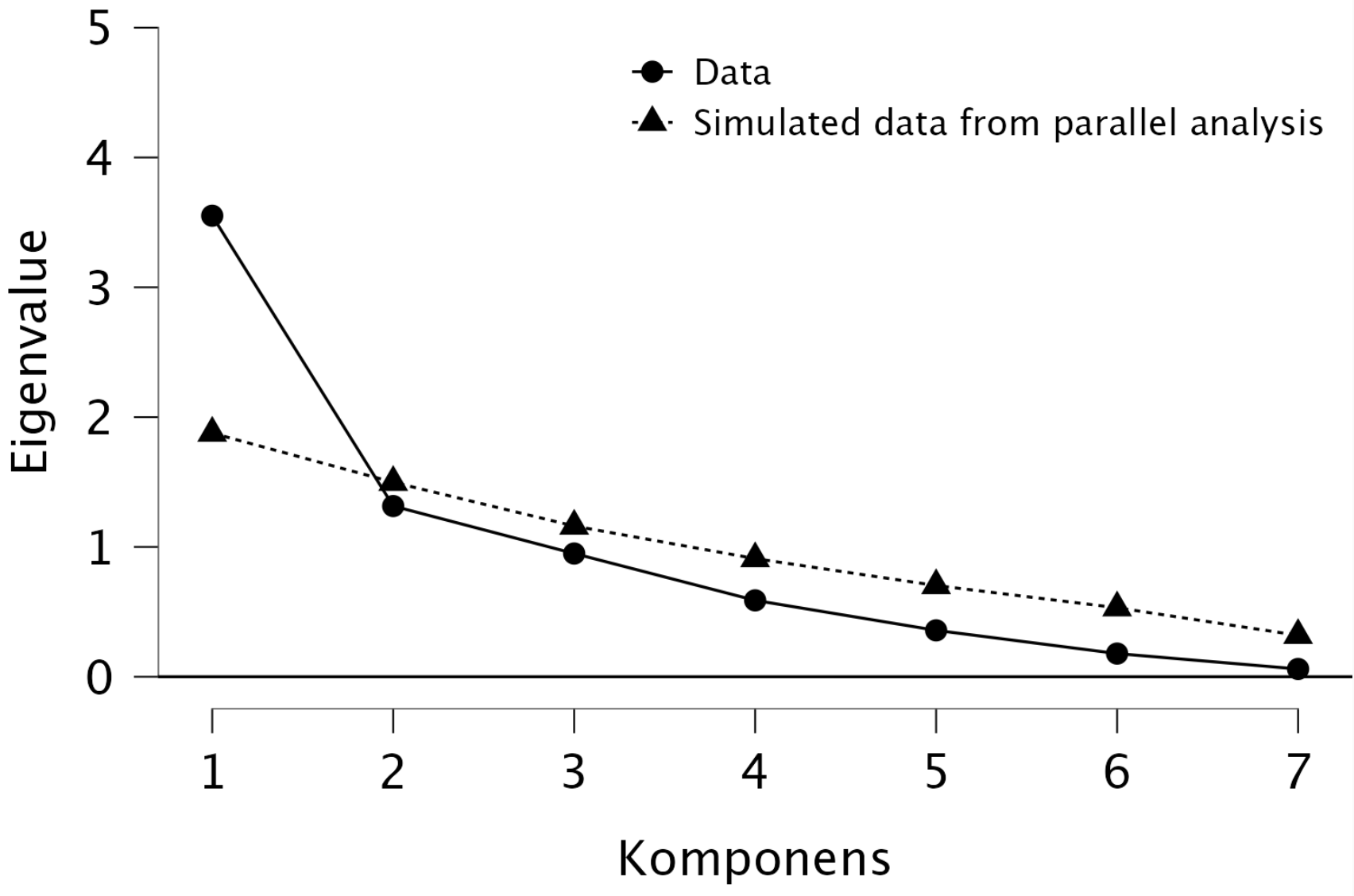
Hogyan döntjük el, hogy hány főkomponenst tartunk meg?
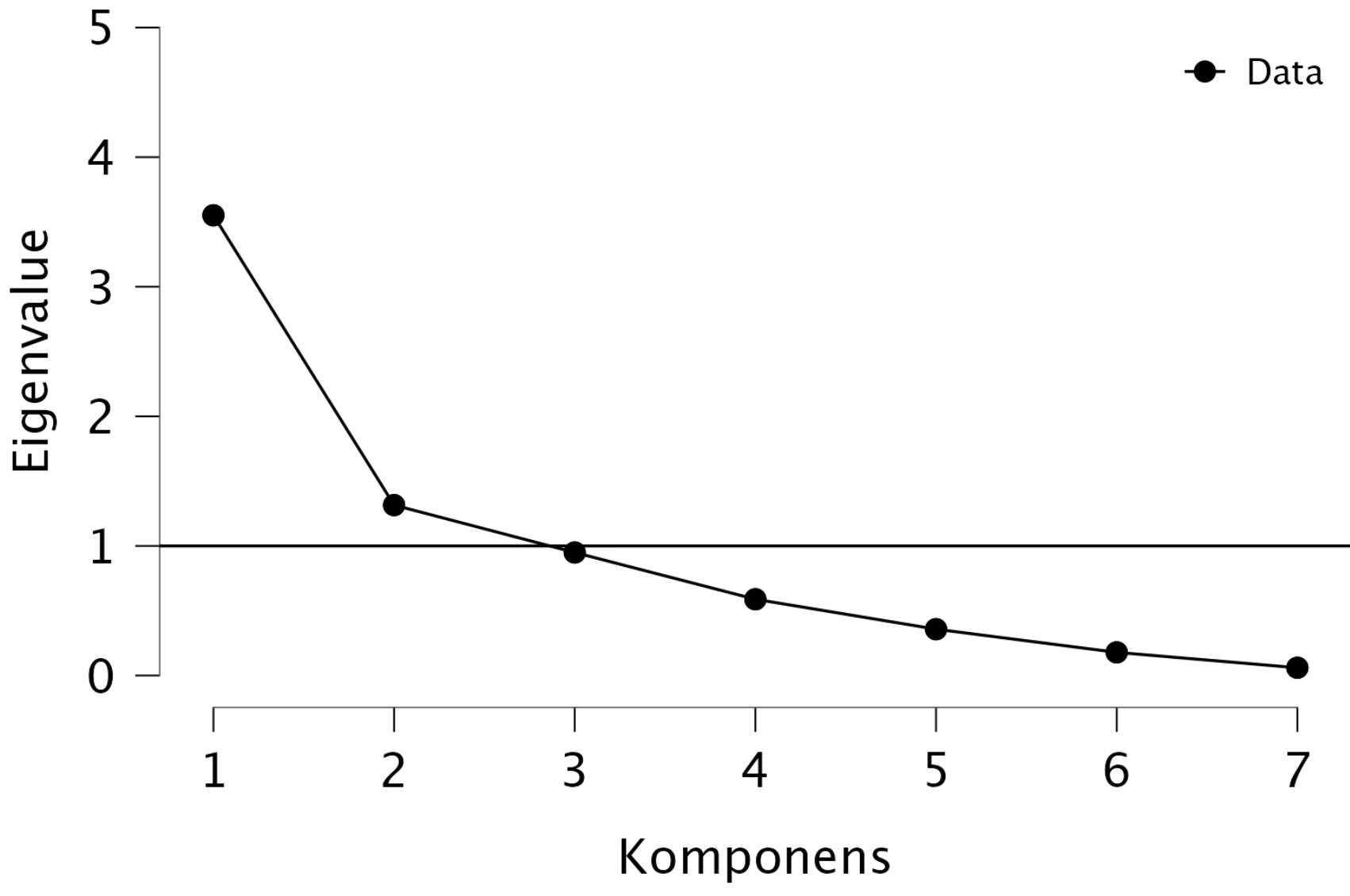
Nézzük meg egy főkomponenselemzés eredményét:
| Főkomponens | Eigenvalue (sajátérték) | Megmagyarázott variancia | Kumulált variancia |
|---|---|---|---|
| Főkomponens 1 | 3,55 | 50,7% | 50,7% |
| Főkomponens 2 | 1,32 | 18,8% | 69,5% |
| Főkomponens 3 | 0,95 | 13,6% | 83,1% |
| Főkomponens 4 | 0,59 | 8,4% | 91,5% |
| Főkomponens 5 | 0,36 | 5,1% | 96,6% |
| Főkomponens 6 | 0,18 | 2,6% | 99,1% |
| Főkomponens 7 | 0,06 | 0,9% | 100,0% |
Megmagyarázott variancia mértéke szerint: Előre definiáljuk önkényesen, hogy mekkora megmagyarázott kumulált varianciát szeretnénk elérni, pl. 80%. Ebben az esetben 3 főkomponenst tartunk meg a fenti példában.
A Kaiser–Guttman kritérium (λ > 1) azt mondja ki, hogy standardizált változók esetén egy komponens legalább annyi varianciát kell magyarázzon, mint egy eredi változó, tehát ha a λ < 1, akkor egy komponens kevesebb varianciát magyaráz (kevesebb információt hordoz), mint egy önálló eredeti változó, amit belesűríteni próbáltunk, így értelmetlen megtartani. Ez esetben a táblázatban látható, hogy az 1. és 2. főkomponens tartható meg.
Scree ploton (könyökábrán) keresünk egy olyan „könyököt”, ahol a sajátértékek csökkenése lelassul, és az első lassulásnál állunk meg. Ez esetben az ábrán látható, hogy az 1. és 2. komponens között meredek a csökkenés, de a 2. és 3. komponens között lelassul, így a lassulás előtti pontnál állunk meg, tehát csak az 1. és 2. komponenst tartjuk meg.
A Horn-féle parallelanalízis a szakmailag legmegalapozottabb döntési mechanizmus (Çokluk és Koçak, 2016; Henson és Roberts, 2006; Lee és Cham, 2024). Az eredeti adatmátrixunkkal egyenlő elemszámú és egyenlő számú változóból álló random adatokat generálunk, és kiszámítunk a sajátértékeket többszöri ismétléssel. Az így kapott sajátértékek 95. percentilisét választjuk mint kritériumszintet. Azokat a komponenseket tartjuk meg, ahol az eredeti adatokból számolt sajátérték nagyobb, mint a kritérium. Itt tehát csak az 1. főkomponens maradhat meg.
Előfeltétel-vizsgálatok
A Kaiser-Meyer-Olkin-féle megfelelőségi mutató (KMO) és a Measures of Sampling Adequacy mutatók (MSA) segítségével azt értékeljük, hogy az adatok megfelelőek-e faktoranalízishez/főkomponens-elemzéshez. Gyakorlatilag a két mutató ugyanaz, csak míg a KMO az összes itemre (a teljes redukálandó adathalmazra) vonatkozik, addig az MSA csupán egyes itemekre. Értékük 0 és 1 közötti értéket vehetnek fel.
Így értelemszerűen JASP-ban a KMO test funkcióval érjük el mindkettőt. Az Overall MSA rovatban található értéket hívjuk majd a Kaiser-Meyer-Olkin-féle megfelelőségi mutatónak, míg az egyes tételek mellé írt értékeket MSA-nak.
\[ \text{KMO} = \frac{\sum{(\text{korrelációk})^2}}{\sum{(\text{korrelációk})^2} + \sum{(\text{parciális korrelációk})^2}} \]
A KMO/MSA értelmezése Kaiser (1974) alapján:
- 0,90+ ideális (marvelous)
- 0,80-0,89 dicséretes (meritorious)
- 0,70-0,79 átlagos (middling)
- 0,60-0,69 középszerű (mediocre)
- 0,50-0,59 siralmas (miserable)
- < 0,50 elfogadhatatlan (unacceptable)
Értelmezésük Hair és mtsai. (2019) alapján:
- 0,8 fölött ideális
- 0,7-től jó
- 0,5-0,7 középszerű
- < 0,50 alatt elfogadhatatlan
Az SPSS az egyes itemekhez tartozó MSA értéket az Anti-image correlation matrix átlójában tünteti fel. Minden átlós értéket a-val jelöl, és megjegyzésben kiírja, hogy ezek az MSA értékek (Measures of Sampling Adequacy).
Bár főkomponens-elemzés bármilyen mátrxion futtatható, a Bartlett-féle szférikusságpróba (Bartlett’s test of sphericity) az itemek teljes korrelálatlanságát teszteli, és általa kiderül, hogy van-e egyáltalán elegendő korreláció az adatredukcióhoz. Nullhipotézise, hogy minden változó független, korrelálatlan és így a korrelációs mátrix egy egységmátrix. Ha szignifikáns (p < 0,05), akkor a változók nem korrelálatlanok, hanem alkalmasak faktorelemzésre, főkomponenselemzésre.
A Mardia-féle többváltozós ferdeségi és csúcsossági mutatót a többváltozós normalitás tesztelésére alkalmazzuk. Ha szignifikáns, akkor a Pearson-féle korrelációs mátrix helyett polikorikus korrelációs mátrixot kell használnunk az adatredukcióhoz.
SPSS-ben mátrixdeterminánst is számolunk: cél, hogy a determináns érték nagyobb legyen, mint 0,00001. JASP-ban nem tudunk mátrixdeterminánst számolni.
Az Anti-Image Correlation Matrixot is elemezhetjük: minden nem átlós érték lehetőleg 0-hoz kell közelítsen (< 0,09). Ez esetben a változók közötti varianciát a közös faktorok magyarázzák, nem pedig párok közötti egyedi parciális korrelációs kapcsolatok.
JASP-ban Az Anti-Image Correlation Matrix átlón kívüli értékeit vizsgáljuk az Assumption checks rovatban az Anti-image correlation matrix kiválasztásával.
Az SPSS-ben látható átlós értékek az MSA értékek, amiket JASP-ban a KMO test funkcióban érhetünk el. Az Overall MSA érték a KMO próba eredménye (ahogy fentebb láttuk), míg az egyes itemek melletti MSA értékek az SPSS-ben található Anti-image korrelációs mátrix átlós értékei.
17.2 Rotáció
A létrehozott főkomponensekről tudjuk, hogy az első főkomponens tartalmazza a mért adatokban fellelhető legnagyobb varianciát, a második a maradékot próbálja magába sűríteni. Ha további variancia fennáll, további főkomponensek jönnek létre, amíg a megmagyarázott variancia el nem éri a 100%-ot.
A rotáció (forgatás) célja, hogy egyszerűbb, értelmezhető struktúrát kapjunk. Leegyszerűsítve, onnan tudjuk, hogy jó rotációs módszert alkalmaztunk, hogy egyszerű struktúrát kaptunk. Az egyszerű struktúra azt jelenti, hogy a változók 1 közeli értékkel töltenek az egyik főkomponensre és 0 közeli értékkel az összes többire.
Mikor NE alkalmazzunk rotációt főkomponens-elemzés során?
TILOS rotációt alkalmazni, ha a főkomponens-elemzés célja a multikollinearitást csökkentése változók között későbbi lineárisregresszió-vizsgálathoz. Ha megengedjük a komponensek közötti korrelációt a ferde rotációval, akkor visszaemeljük a modellbe a multikollinearitás egy részét. Ortogonális (független) rotációt pedig azért nem alkalmazunk, mert a PCA lényege a variancia-magyarázat mértéke szerinti rangsorolás, de az ortogonális rotáció „szétteríti” a varianciát a komponensek között, így nem biztos, hogy a legfontosabb k számú komponenst tartjuk meg.
NE alkalmazzunk rotációt, ha egyszerű dimenzióredukció a célunk maximális variancia megtartása mellett (a fent említett „szétterítés” okán).
Rotációs módszerek
Két fő rotációs módszert különböztetünk meg:
Ortogonális rotáció (orthogonal rotation): derékszöget, függetlenséget megtartó rotáció. Feltételezése, hogy a komponensek/faktorok korrelálatlanok (r = 0). Főbb variánsai:
Varimax (alapértelmezett választás egyszerű struktúrához): A faktorok (oszlopok) mentén maximalizálja a négyzetes töltések varianciáját, innen a neve. A célja, hogy minden faktoron csak néhány változónak legyen extrém nagy töltése, minden más változónak minimális.
Quartimax (ha minél kevesebb faktort akarunk): A változónkénti (soronkénti) komplexitásra fókuszál, kevés faktorra nagy töltést produkál.
Equamax: A varimax és quartimax közötti technika, faktoronkénti magas töltéseket próbálja minimalizálni
BentlerT: A Bentler-féle invariáns mintázat-egyszerűsítési elven alapuló módszer, ami arra törekszik, hogy minden változó csak egy faktorhoz legyen erősen köthető, a többihez közel 0 legyen a töltése.
GeominT: A Bentler-hez hasonlóan a változókat optimalizálja, minimalizálva az egyes változók négyzetes töltések szorzatát.
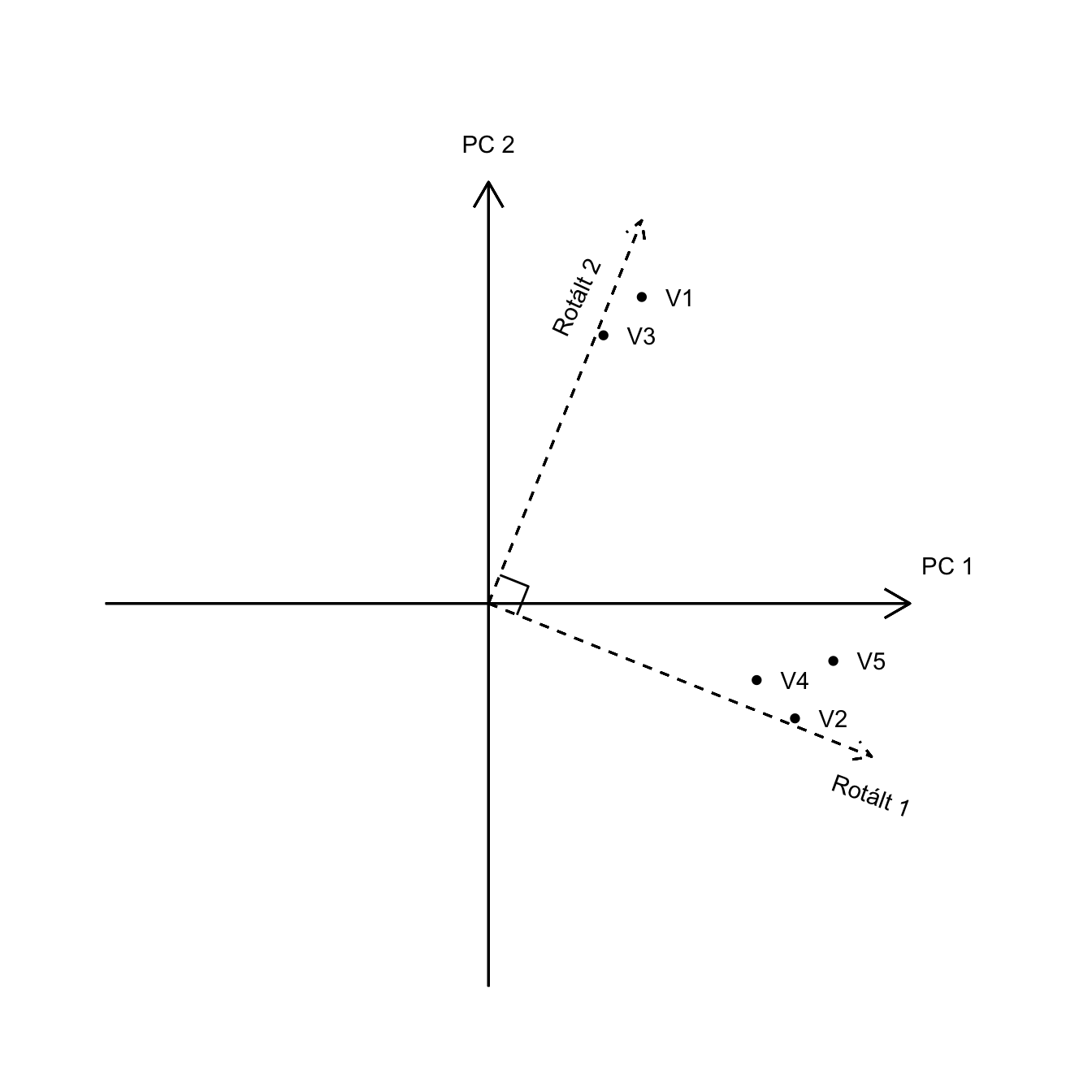
Ferde rotáció (oblique rotation): derékszöget és függetlenséget nem tartó rotáció. Feltételezi, hogy a komponensek/faktorok között van korreláció (|r| > 0). Szociológiai-pszichológiai kutatásokban szinte lehetetlen, hogy ne legyen a látens faktorok között korreláció, így a pszichológiai kutatási munkában — különösen indokolt eseteken kívül — ezt a rotációtípust választjuk (Osborne és mtsai., 2008). Főbb variánsai:
Promax (ajánlott forgatási típus, nagyméretű adathalmaz esetén különösen): Gyors, robusztus és stabil. A varimax rotáció eredményeit veszi alapul, majd k hatványra emeli és ehhez az ideális célmátrixhoz forgat ferdén.
(Direct) Oblimin család (másodlagos választás a promax helyett, egy „best guess” struktúrára használjuk): A sorok egyszerűsítésére optimalizál, ahogy a Bentler és Geomin rotációk is, de túlzottan korrelált faktorokat produkálhat. Minimalizálja a kovarianciát a komponenspárok között. Az egyszerű struktúra elérésére a leginkább alkalmas. Alvariánsai:
- Quartimin (a default oblimin): γ = 0, legferdébb
- Biquartimin: γ = 0,5, kevésbé ferde, ajánlott!
- Covarimin: γ = 1, nem ferde
BentlerQ: A BentlerT párja. Maximalizálja a Bentler skálainvariáns sor-egyszerűségi indexét. Nagyon robusztus.
GeominQ (komplex adatkészlet esetén): A GeominT párja. Minimalizálja változónként a négyzetes töltések szorzatát (ε).
Simplimax: Tiszta szerkezetre fókuszál, azt keresi, hol van a legtöbb „majdnem 0” értékű töltés.
Cluster: Egy idealizált cluster-struktúrához forgat. Arra törekszik, hogy minden változó egyetlen faktoron töltsön magasan, a többin pedig minimálisan. Q-methodhoz ajánlott.
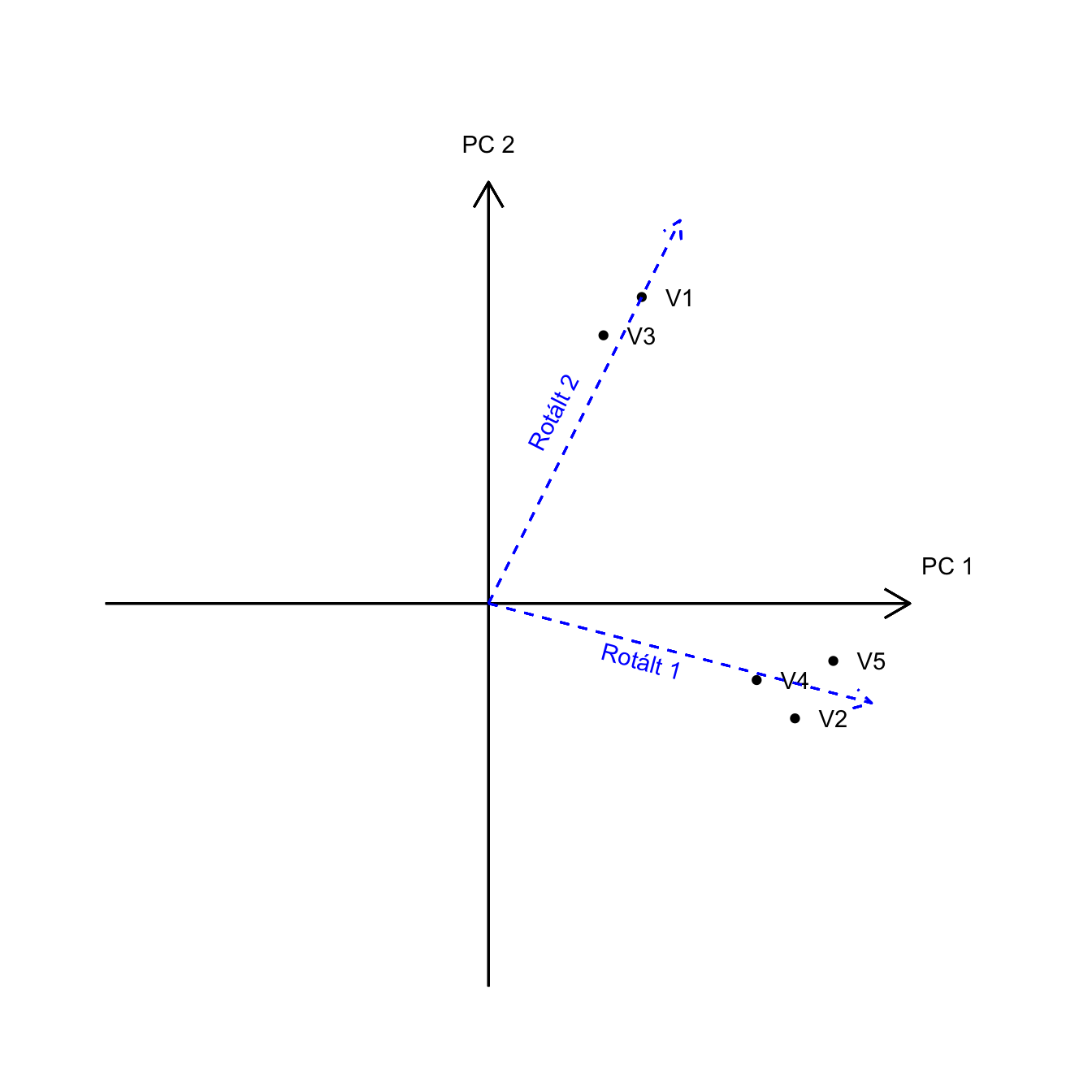
17.3 A töltések (loadings) értékelése
Miután meghatároztuk a főkomponensek számát és elvégeztük a rotációt, a következő lépés a (rotált) komponensmátrix értelmezése. A töltések a mért változó és a főkomponens közötti korrelációt fejezik ki, értékük -1 és +1 között mozog.
A töltések küszöbértékei, szignifikanciája
A pszichológiai kutatásokban a töltések értékelésére több mód is létezik:
Ökölszabály: A |0,32| alatti töltések elhanyagolhatóak. Megjegyzés: a JASP 0,40-s küszöbértéket használ alapértelmezetten.
Minőségi besorolás Comrey és Lee (2013) alapján:
- 0,71- : kitűnő
- 0,63-0,70: nagyon jó
- 0,55-0,62: jó
- 0,45-0,54: közepes
- 0,32-0,44: gyenge
- < 0,32: nem értelmezhető
Mintaelemszám szerinti értékelés: Hair és mtsai. (2019) szerint a küszöb a mintaelemszámtól függ:
Mintaelemszám (N) Faktortöltés küszöbértéke 50 0,75 60 0,70 70 0,65 85 0,60 100 0,55 120 0,50 150 0,45 200 0,40 250 0,35 300 0,30 Modern vegyes megközelítés: Pituch és Stevens (2015) alapján:
- minden komponens/faktor legalább négy db, abszolút értékben legalább |0,60| töltésű itemmel kell rendelkezzen.
- 10 vagy annál több alacsony töltésű (< |0,40|) itemmel rendelkező komponens reliábilis, ha a mintaelemszám nagyobb, mint 150.
- Hagyjuk figyelmen kívül azokat a komponenseket, amelyekhez csak pár item tölt alacsony értékkel és a mintaelemszám se éri el a 300-t.
Struktúraelemzés
Akkor érjük el az egyszerű struktúrát, ha minden tétel csak egyetlen főkomponenshez tartozik (ti. erősen tölt adott főkomponenshez), a többihez pedig csak minimálisan kapcsolódik (ti. alacsony a töltés más főkomponenshez).
Kereszttöltésnek nevezzük azt a jelenséget, amikor egy tétel több komponensre is szignifikánsan tölt (pl. > 0,3, > 0,32 vagy > 0,4 küszöbérték). Ha adott tétel esetén a két töltés közötti különbség kisebb, mint 0,2, akkor a tétel nehezen besorolható, értelmezhető. Ekkor töröljük a tételt vagy felülvizsgáljuk az alkalmazott rotációs eljárást.
Kommunalitáskontroll során megvizsgáljuk, hogy a modellünk (a megtartott főkomponensek) mennyire jól reprezentálják az eredeti változóinkat. A JASP-ban az egyes itemekhez tartozó egyediség (Uniqueness) oszlop reprezentálja azt, hogy a közös faktorok az adott tétel varianciájának mekkora részét nem magyarázzák (ti. 1 - kinyert kommunalitás). Magas egyediség (> 0,6) azt jelenti, hogy a változó nagy részében egyedi variancia, mérési hiba található, amit a többi változóval alkotott közös komponensek nem tartalmaznak. SPSS-ben kinyert kommunalitás (extraction) érhető el, értelemszerűen a 0,4 alatti kommunalitás értéket elérő változók nem illeszkednek jól a modellbe.
A főkomponens-elemzésben kialakított modellünknek is vannak maradványértékei. A maradványértékek mátrixát ellenőriznünk kell. A mátrix átlója a fentebb ismertetett egyediséget mutatja ismét, de számunkra a mátrix átlóján kívüli tételek fontosak. Lehetőleg csak az átló alatti vagy a feletti értékeket vizsgáljuk; mindkettőt nem kell, hiszen ezek egymás tükörképei.
- A cél, hogy a lehető legtöbb átlón kívüli érték |0,05| alatti legyen (tehát > -0,05 vagy < 0,05). Egy gyakorlati kritérium, hogy a fenti küszöbérték fölötti értékek darabszáma ne haladja meg az 50%-ot. (Ezt a vizsgálatot R-ben vagy Excelben tudjuk megtenni.)
- Extrém magas maradványérték (> |0,30|) esetén újabb főkomponens szükséges!
- Egy másik megközelítés, hogy az átlón kívüli érték négyzetösszegéből gyököt vonunk, és ez az érték ideális esetben kisebb, mint 0,08 (Field és mtsai., 2014). Ha ennél nagyobb, akkor érdemes még egy főkomponenst találnunk. (Ezt a vizsgálatot R-ben tudjuk elvégezni, JASP-ban jelenleg nem elérhető.)
17.4 Példa főkomponenselemzésre
Kérdőíves vizsgálatot végeztünk (N =) 350 fővel, amiben 25 állítást kellett értékelni 6-fokú skálán. Az állítások a személyiség aspektusait vizsgálják. Szeretnénk az adatokat redukálni további elemzések elvégzése érdekében, ezért főkomponens-elemzést végzünk. (Azt várjuk, hogy a Big Five személyiségstruktúra jön ki.)
Az adatfájl letölthető: bfi.sav
JASP-ban megnyitjuk a letöltött fájlt és biztosítjuk, hogy nem skálaváltozóként, hanem ordinális változóként legyen beállítva mind a 25 mért változó. Ez azért fontos, mert ha polikorikus korrelációs táblát kell válasszunk, az csak akkor elérhető, ha ordinális mérési szint van beállítva.
A főkomponens-elemzést a Factor / Principal Component Analysis modulban végezzük el. Beállítjuk a vizsgálatot az alábbiak szerint:
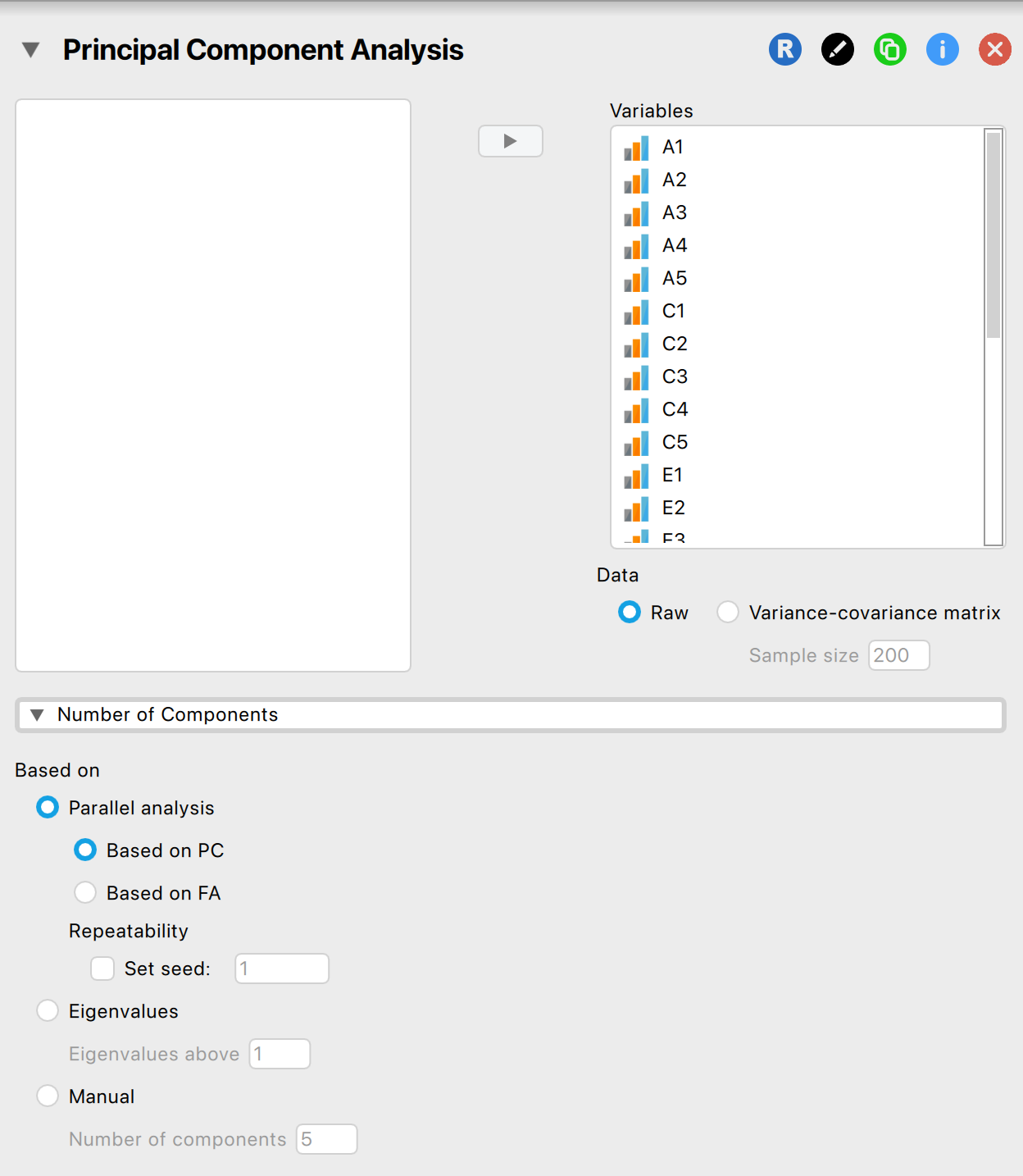
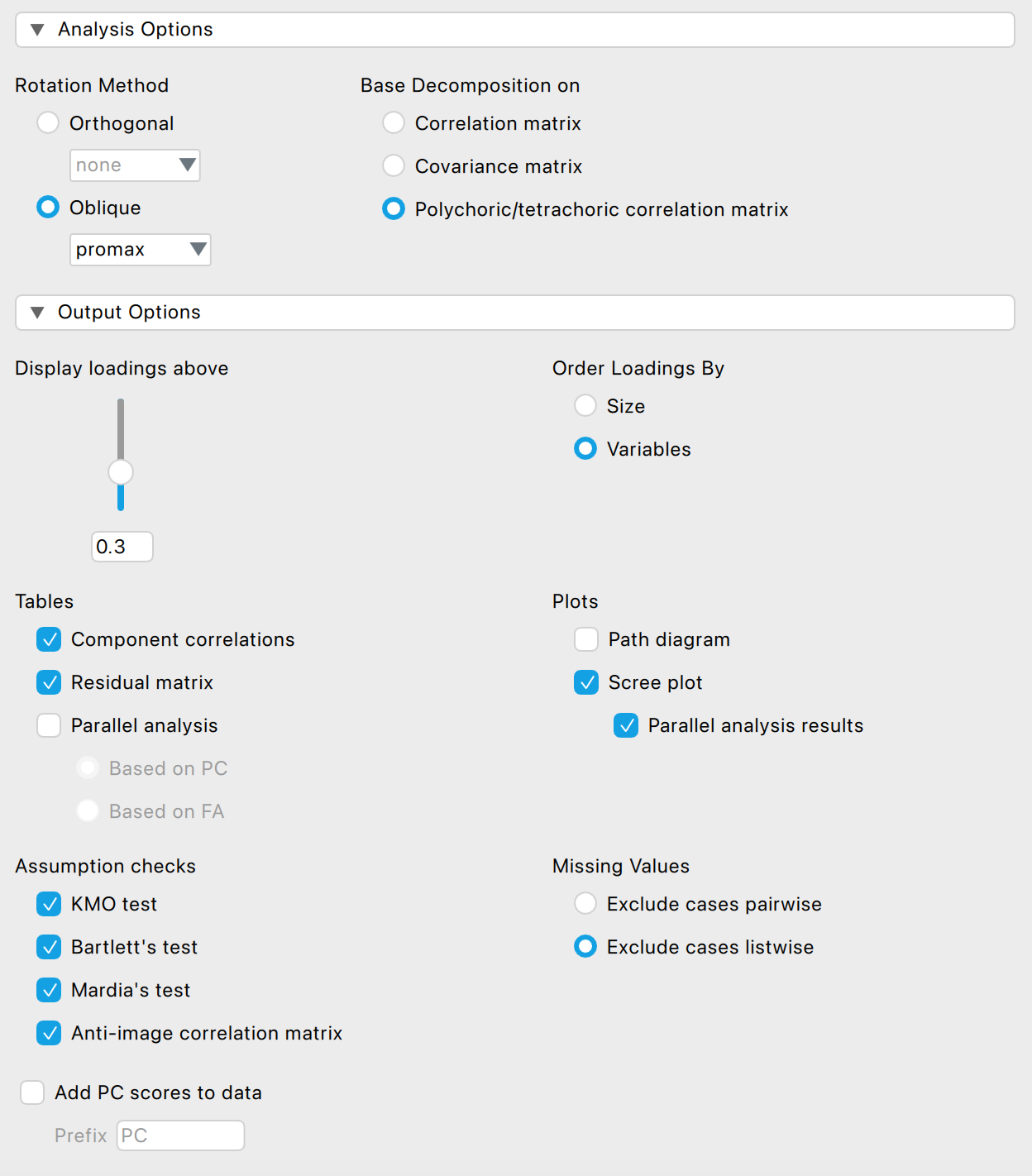
A beállításokat az alábbiak szerint végeztük el:
- Number of components szekcióban a Based on rovaton belül a Horn-féle parallelanalízist választjuk (Parallel analysis), azon belül pedig - mivel főkomponenselemzést végzünk (PC) és nem faktoranalízist (FA) - a PC opciót választjuk.
- Rotáció az Analysis Options szekcióban
- Ha ortogonális rotációt (pl. varimax) választunk, akkor azt feltételezzük, hogy a redukált struktúra komponensei között nincs korreláció.
- Ha ferde (oblique) rotációt (pl. promax) választunk, akkor feltételezzük, hogy a redukált struktúra komponensei valamilyen mértékben korrelálnak egymással. Mivel big five személyiségvonásokat várunk, helyesebb lenne azt feltételezni, hogy a főkomponensek nem függetlenek egymástól, így inkább ezt válasszuk (pl. promax)!
- Mátrix kiválasztása a Base Decomposition on szekcióban: tudjuk, hogy polikorikus korrelációs mátrixot főleg ordinális adatoknál, vagy kimondottan Likert tételeknél célszerű használni, így ezt választjuk ki a biztonság kedvéért. Ha a Mardia-féle mutatók nem szignifikánsak, akkor biztonságosan választhatjuk a Pearson-féle korrelációs mátrixot helyette.
- Az Output options szekcióban…
- állítsuk be, hogy a |0,3| fölötti komponenstöltéseket láthassuk (az alapbeállítás 0,4): Display loadings above
- állítsuk be, hogy a komponenstöltések táblázatában ne a töltések erőssége, hanem a változók nevének sorrendjében jelenjenek meg a változóink: Order Loadings By Variables
- állítsuk be, hogy a hiányzó értékeket (Missing Values) listwise töröljük! Ez esetben az elemzés minden olyan adatsort kihagy, ahol hiányzó érték szerepel. Ha a pairwise opciót választjuk, akkor több adatunk marad meg az elemzéshez, de a torzítás is nő, vagy fennáll a kockázata az inkonzisztens korrelációs mátrixok előállásának.
- pipáljuk ki a Tables rovatban a Component correlations lehetőséget, mert ferde rotációt alkalmaztunk és tudni szeretnénk, hogy milyen korreláció áll fenn a főkomponensek között.
- pipáljuk ki a Tables rovatban a Residual matrix lehetőséget, mert ellenőriznünk kell, hogy a modellünk maradványértékei alacsonyak.
- pipáljuk ki a Plots rovatban a Scree plotot és a Parallel analysis results-t, ami alapján döntünk a megtartott komponensek számáról.
- pipáljuk ki az Assumption cheks szekció összes mezőjét, de minimum a KMO test, Bartlett’s test opciókat!
- Olvassuk le az előfeltétel-vizsgálatok eredményeit!
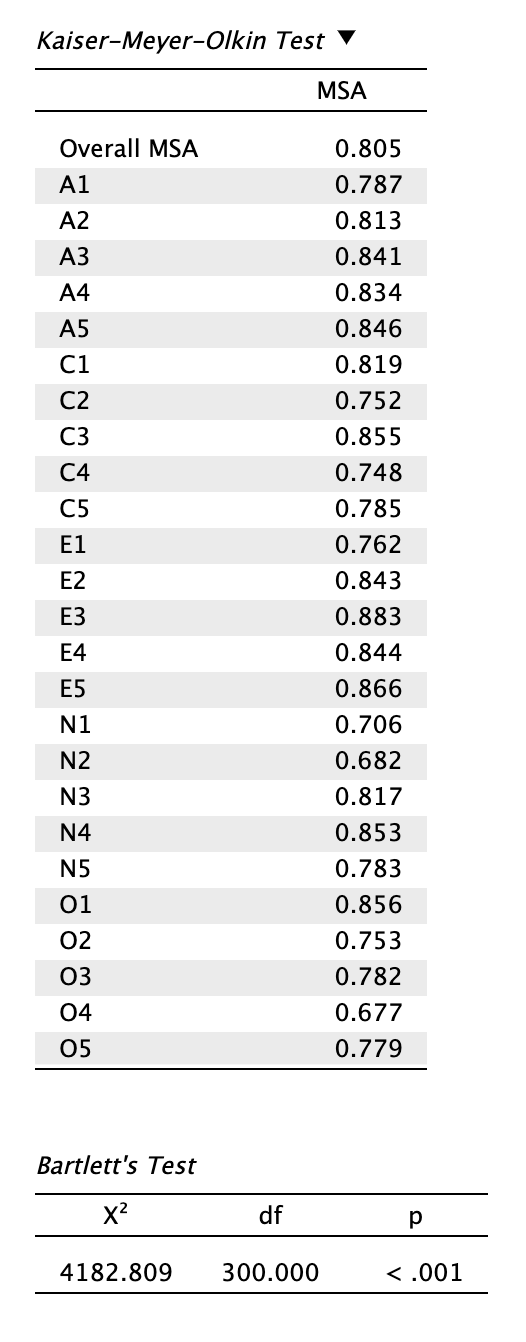
Láthatjuk, hogy a Kaiser-Meyer-Olkin-féle megfelelőségi mutató (Overall MSA) értéke 0,805, ha a polikorikus korrelációs mátrixot1 választottuk. Ez dicséretes Kaiser (1974) alapján, vagy ideális Hair és mtsai. (2019) alapján.
Az egyes tételekhez tartozó Measures of Sampling Adequacy mutatók (MSA) vegyesebb képet mutatnak: 0,677 (O4 tétel) és 0,883 (E3 tétel) között mozognak. Egyik tétel pontszáma sem 0,5 alatti, ezért nem kötelező törölnünk tételeket a modellből. Eldönthetjük, hogy kihagyjuk-e őket az elemzésből, ha erős elméleti alapunk van rá, vagy csupán jelentjük őket szövegesen. Ebben a példában értelemszerűen ez utóbbit választjuk.
A Bartlett-féle szférikusságpróba eredménye szignifikáns, vagyis a tételek közötti korreláció elégséges főkomponens-elemzéshez (és faktoráláshoz): a korrelációs mátrix nem egységmátrix.
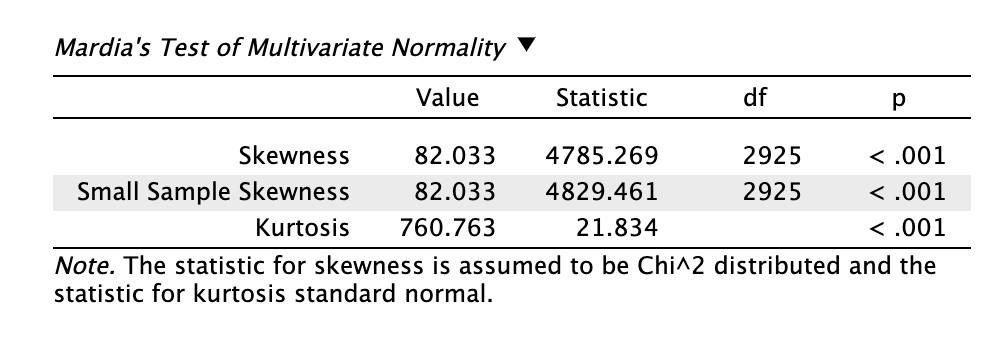
A többváltozós normalitás vizsgálata során azt látjuk, hogy mind a túlzott ferdeség, mint a túlzott csúcsosság fennáll (szignifikáns mindegyik próba). Ezért Pearson-féle korrelációs mátrixot használni nem javallot. Helyette a polikorikus korrelációs mátrix használata célszerű (nem hiába választottuk azt a biztonság kedvéért alapválasztásként).
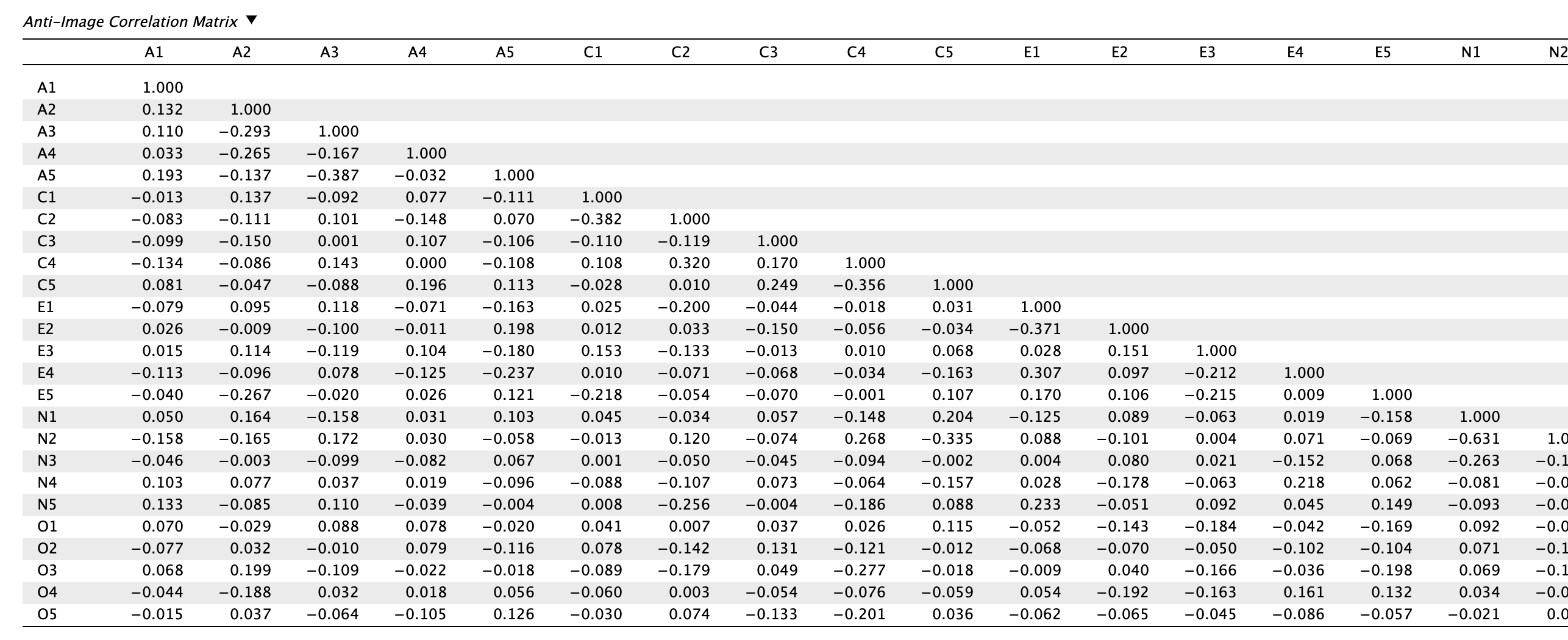
Az anti-image korrelációs mátrixot áttekintjük, és megvizsgáljuk, hogy vannak-e nullánál lényegesen nagyobb tételek (≥ 0,09) abszolút értékben. Sajnálatos módon több tételpárnál láthatunk nagyon magas parciáliskorrelációs értékeket, például:
- N1-N2: -0,631
- A3-A5: -0,387
- C1-C2: -0,382
- E1-E2: -0,371
- N3-N4: -0,368
Ez azt jelenti, hogy a mátrix jelenleg nem optimális, mert az itemek között páronként szisztematikus variancia van, amelyeket a főkomponens-elemzésben felállított főkomponensek nem fognak megfelelően lefedni, így például redundáns faktorok/komponensek állhatnak elő. Pszichometriai szempontból érdemes megvizsgálni, hogy például az N1 és N2 tételek nem mérik-e nagyon szűken ugyanazt a jelenséget.
Együttesen az előfeltételvizsgálatok azt az eredményt adják, hogy az adatstruktúra alkalmas főkomponenselemzésre (és faktoranalízisre is), az MSA értkek stabilak, bár egyes tételek túl hasonló varianciát hordoznak, ezért várhatóan nagyon magasan töltenek majd ugyanarra a komponensre.
- Nézzük meg a scree plotot és a parallelanalízis eredményét!
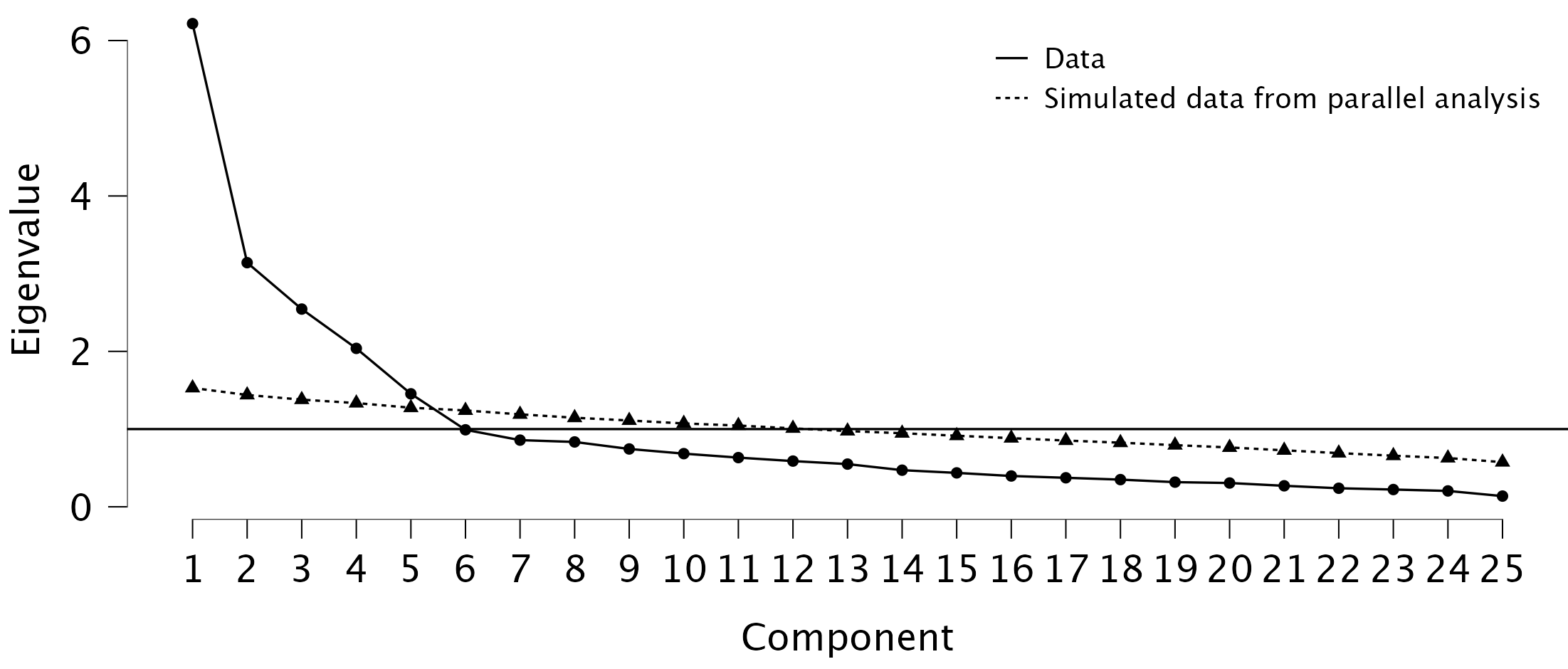
Láthatjuk, hogy ha pusztán a könyökábra meredekség-csökkenése alapján értékelnénk, akkor vagy két komponenst tartnánk meg, vagy hatot. Ha a Kaiser—Guttman-kritérium alapján ítélünk (eigenvalue > 1), akkor éppenhogy 5-t. A Horn-féle parallelanalízis — ami a modernebb kritérium — eredménye 5 főkomponens. (Mellékesen tudjuk, hogy a Big Five itemek 5 komponenst kellene eredményezzenek.)
- Olvassuk le rotált töltéseket!
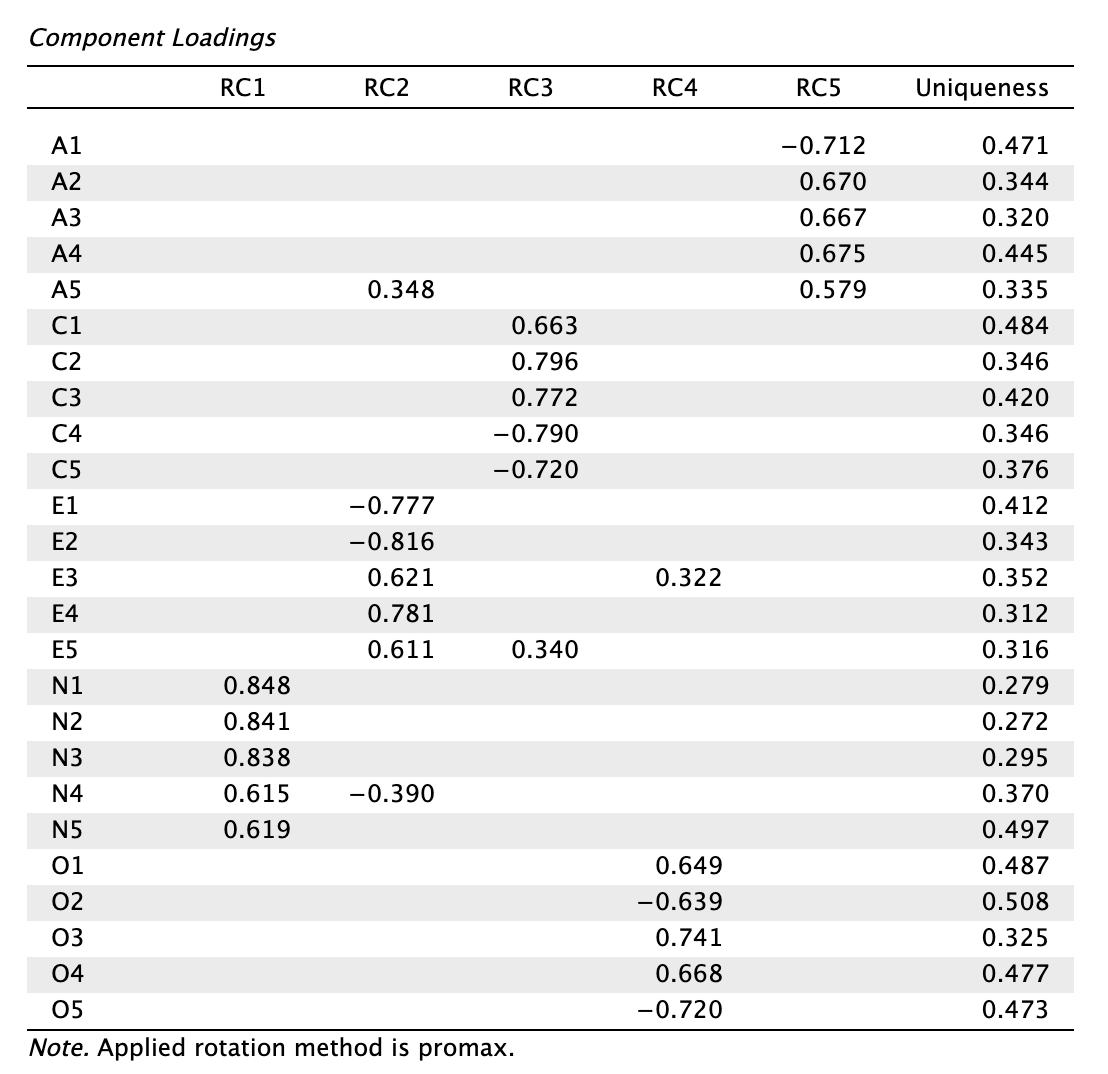
Az 5 db rotált komponens (RC1-RC5) töltéseit Comrey és Lee (2013) alapján értékeljük (abszolút értékben), majd a kereszttöltéseket és az egyediséget is vizsgáljuk.
Az RC5 rotált főkomponensre 5 tétel töltött erősen. A tételeket ismerve elnevezhetjük ezt a komponenst Agreeableness-nek (Barátságosság). Az A1 tétel kitűnő (bár fordított irányú tétel a többihez képest), az A2—A4 tételek pedig nagyon jó töltéssel rendelkeznek. Az A5 tétel töltése csupán jó, de szignifikáns kereszttöltéssel (> 0,32) rendelkezik az RC2 komponensre. A két töltés közötti különbség > 0,2 (\(0{,}579-0{,}348=0{,}231\)), ami alapján a tétel egyértelműen besorolható az RC5 komponenshez. Ez azt jelenti, hogy a tétel a varianciájának legalább 10%-át egy másik komponens magyarázza. (Bár ne feledjük, főkomponens-elemzés során minden variancia közös variancia, az értelmezést mégsem tudjuk máshogy megtenni.) Az A1 és A4 tételek rendelkeznek a legnagyobb egyediséggel (egyedi variancia, amit nem magyaráznak a komponensek).
Az RC3 komponens a Conscientiousness (Lelkiismeretesség). A C2, C3, C4 és C5 tételek töltése kitűnő (bár a C4 és C5 negatív irányú), míg a C1 töltése nagyon jó. Ebben a faktorban nem azonosítható 0,32 feletti szignifikáns kereszttöltés. Az egyediség a C1 és C3 tétel esetén a legmagasabb, míg a C2 és C4 és C5 tételek varianciáját magyarázzák leginkább a komponensek.
Az RC2 főkomponens az Extraversion (Extraverzió) Big 5 dimenziót fedi le. Az E1, E2 és E4 tételek kitűnő töltéssel rendelkeznek, az E3 nagyon jó, az E5 pedig jó. Kereszttöltések tekintében az E3 az RC4-re (0,322), az E5 pedig az RC3-ra (0,340) tölt szignifikánsan (> 0,32). Mindkét esetben teljesül a >0,2-es különbségi szabály, így az RC2-höz való hozzárendelésük statisztikailag alátámasztott. Az E1 tétel rendelkezik a legmagasabb egyediséggel (0,412), ami azt jelzi, hogy e tétel varianciájának jelentős része nem magyarázható az RC2 komponenssel.
Az RC1 rotált főkomponensre 5 tétel töltött erősen, ez a Neuroticism (Neuroticizmus). Az N1, N2 és N3 tételek kitűnő töltéssel bírnak, de az N4 és N5 tételek töltése csak jó. Az N4 tétel szignifikáns kereszttöltéssel (−0,390) rendelkezik az RC2 komponensre, azonban a két töltés közötti különbség (\(0{,}615−0{,}390=0{,}225\)) meghaladja a 0,2-es határértéket, így a tétel besorolása az RC1 komponensre megfelelő. Az N5 tétel mutatja a legnagyobb egyediséget.
Az RC4 rotált főkomponens az Openness (Nyitottság). Az O3 és O5 tételek kitűnő, az O1, O2 és O4 tételek pedig nagyon jó töltésűek (az O2 és O5 tételek fordított irányúak). Szignifikáns kereszttöltés nincs (az ide töltő E3-n kívül). Az O2 tételnek van a legmagasabb egyedisége (0,508), ami azt jelenti, hogy a varianciájának több mint a felét nem a Nyitottság főkomponens magyarázza.
Tételeket nem szükséges törölni, a struktúra stabilnak tekinthető.
- A rotáció indokoltságának ellenőrzése ferde rotáció miatt
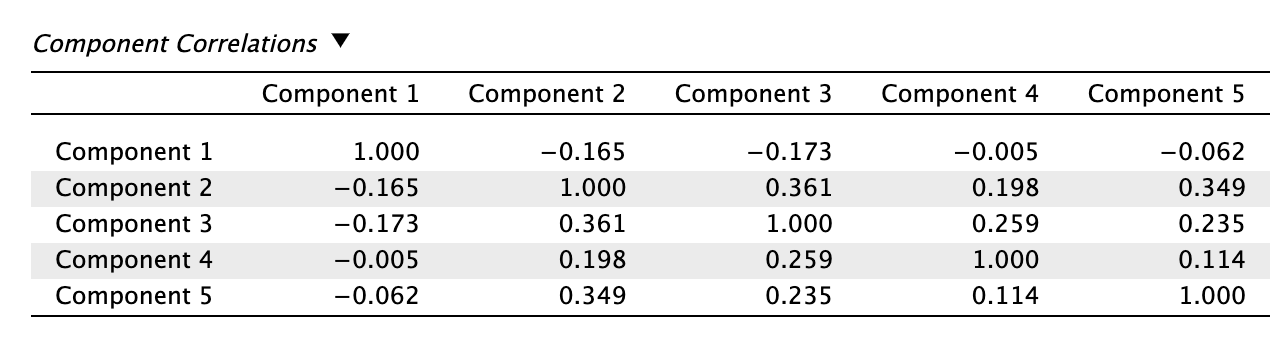
A ferde (oblique) rotációval (promax) azt feltételeztük (pszichológiai ismereteink alapján nagyon is helyesen), hogy a főkomponensek között van korreláció. A komponensek közötti korrelációs táblával ezt ellenőrizni tudjuk. A táblázatban jelentős (r > 0,32) interkorrelációkat láthatunk, ami indokolja a ferde rotációt!
- RC2 és RC3 között r = 0,361
- RC2 és RC5 között r = 0,349
- (RC3 és RC5 között r = 0,235)
- Maradványértékek mátrixának ellenőrzése
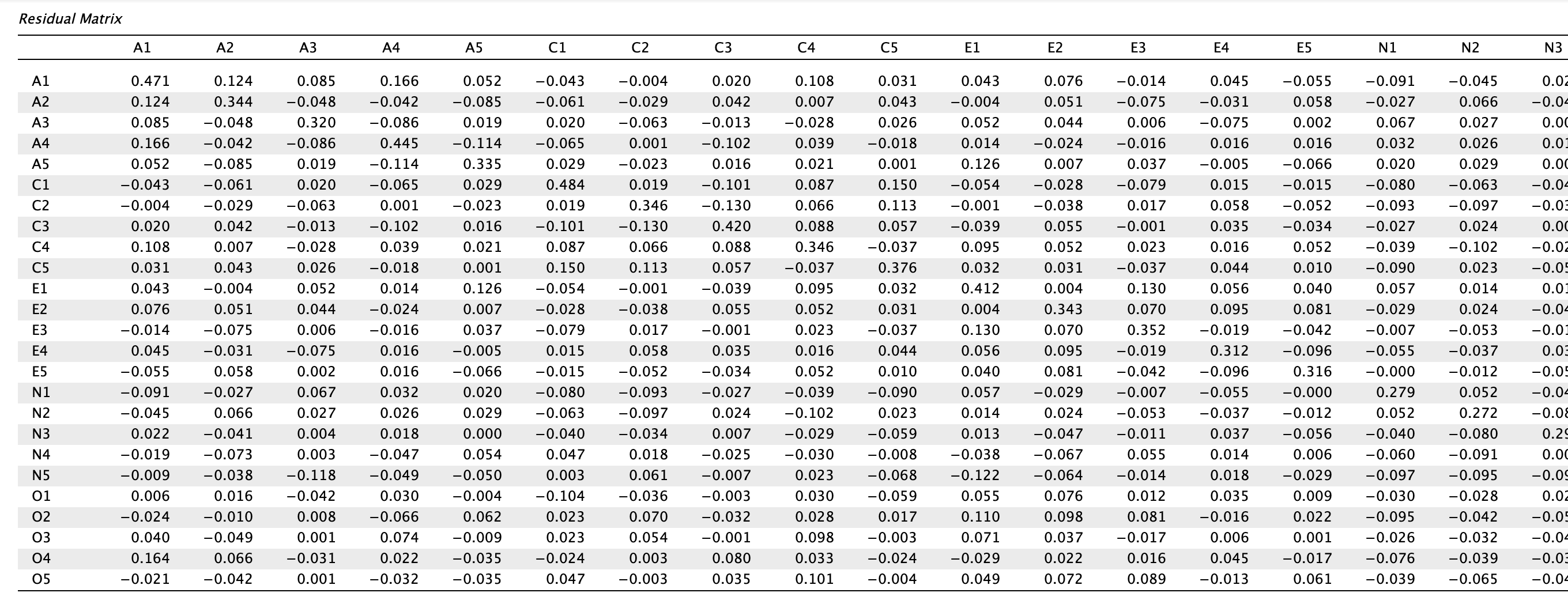
JASP-on kívül, pl. Excelbe másolással, vizsgáljuk meg, hogy az átló alatti vagy feletti tételek hány százaléka < -0,05 vagy > 0,05. Cél, hogy a küszöbértéken túli értékek száma kisebb legyen, mint 50%.
Láthatjuk, hogy a mátrix nagy részében az értékek (abszolút értékben) alacsonyak, tehát az 5 komponens megfelelően és takarékosan (parsimoniously) nyerte ki a közös varianciát. Maradtak azonban jelentős varianciák egyes változópároknál (pl. A1-A4, A1-O4, C1-C5, O2-O4, O3-O5). Extrém magas (> |0,30|) maradványértékek nincsenek. Összesen 109 változópár maradványértéke magasabb, mint |0,05|, de ez csupán a párok 36%-át teszi ki.
Az Excel példa (számításokkal, képletekkel) letölthető: bfi_maradvanyertekek.xlsx
A modell elfogadható és robusztus.
Megoldás 17.1. [Módszerek]
A személyiség aspektusait mérő 25 tétel dimenziócsökkentése érdekében főkomponens-elemzést (PCA) végeztünk promax típusú ferde (oblique) rotációval. A Kaiser-Meyer-Olkin (KMO) és MSA mutatók értelmezéséhez Kaiser (1974) és Hair és mtsai. (2019) kritériumait alkalmaztuk. A többváltozós normalitás ellenőrzésére Mardia-féle normalitáspróbákat végeztünk. Szignifikáns eredmény esetén polikorikus korrelációs mátrixot alkalmazunk a főkomponens-elemzéshez, mert a Pearson-féle korrelációs mátrix alábecsüli a valódi kapcsolatot a tételek között Kiwanuka és mtsai. (2022). A fennmaradó parciális korrelációkat anti-image korrelációs mátrix alapján értelmeztük (< 0,09 kritériumszint).
A megtartandó főkomponensek számát Horn-féle parallelanalízissel határoztuk meg. A ferde rotáció szükségességét a komponens korrelációs mátrixszal ellenőriztük, ahol a > 0,32 értékeket tekintettünk indokoltnak. A modellilleszkedést a maradványértékek mátrixával diagnosztizáltuk: a |0,05|-nál nagyobb értékű tételpárok arányát 50% alatt határoztuk meg, továbbá kerestünk extrém (> |0,30|) maradványértékeket. A töltések értékelésekor a 0,3-es alatti töltéseket mellőztük. Kereszttöltés esetén a tételt akkor tekintettük egyértelműen besorolhatónak, ha a két legnagyobb töltés közötti különbség meghaladta a 0,2-t.
[Eredmények]
Az adatok alkalmasnak bizonyultak főkomponens-elemzésre: a Kaiser–Meyer–Olkin mutató dicséretes volt (KMO = 0,805), az egyes tételek MSA értékei (0,677-0,883) kivétel nélkül meghaladták a 0,500-s szintet. A Bartlett-féle szférikusságpróba eredménye szignifikáns (χ2(300) = 4182,81, p < 0,001), ami megerősítette, hogy a tételek közötti korrelációk elégségesek az adatredukcióhoz. Mivel a Mardia-féle mutatók a többváltozós normalitás sérülését jelezték (szignifikáns ferdeség és csúcsosság, p < 0,001), az elemzést polikorikus korrelációs mátrixon futtattuk.
A Horn-féle parallelanalízis eredménye alapján öt főkomponens megtartását javasolta, valamint ezt támasztotta alá a Kaiser–Guttman-kritérium is. A ferde (promax) rotáció alkalmazását a főkomponensek közötti jelentős (r > 0,32) interkorrelációk (RC2-RC3: r = 0,361, RC2-RC5: r = 0,349) indokolták. A tételek tartalmi elemzése alapján az öt komponens neve: barátságosság (RC5), lelkiismeretesség (RC3), extraverzió (RC2), neuroticizmus (RC1) és nyitottság (RC4).
A kereszttöltések vizsgálata során több tétel (A5, E3, E5, N4) mutatott másodlagos töltést, de minden tétel besorolása statisztikailag egyértelmű volt (különbség >0,20). A modell illeszkedése megfelelő volt: a maradványértékek 36%-a (< 50%) haladta meg a |0,05| küszöböt, valamint extrém magas (> |0,30|) érték nem volt. A tételek egyedisége (0,272-0,508) átlagosan megfelelő volt (< 0,6), ami azt jelzi, hogy a kinyert komponensek a tételek varianciájának jelentős részét magyarázzák. A komponenstöltéseket és a változók egyediségét a … táblázat tartalmazza:
… táblázat
A 25 itemes kérdőíven elvégzett főkomponens-elemzés ferde (promax) forgatás utáni mintázatmátrixa (N = 350)

Megjegyzés. RC1 = Neuroticizmus; RC2 = Extraverzió; RC3 = Lelkiismeretesség; RC4 = Nyitottság; RC5 = Barátságosság. A ∣0,3∣ alatti töltéseket mellőztük.
Ettől eltérő értéket kapnánk, ha a korrelációs mátrix lenne kiválasztva.↩︎